遅すぎる `pandas.read_gbq` を使わずに、Google BigQueryから高速にデータを読み込む
pandas.read_gbq 便利ですよね。 クレデンシャルファイルを認証画面からコピペすれば Jupyter Notebook 上で簡単に認証され、Google BigQuery が実行されてその結果がそのままデータフレームとして扱えます。 Jupyter Notebook と Google BigQuery を連携させたいときは愛用していました(過去形)。
問題点
- そこそこ大きなデータを持ってこようとすると、めちゃくちゃ遅くてストレスが凄い
解決方法として、Google BigQuery で巨大なデータをダウンロードする方法について書きます。
実は Google の公式ドキュメントでも推奨されています。
- https://cloud.google.com/bigquery/docs/pandas-gbq-migration
- https://cloud.google.com/bigquery/docs/bigquery-storage-python-pandas
方法は以下の2つ。
google-cloud-bigqueryをインストールして、マジックコマンドで Google BQ を実行- BQ 実行 →BigQuery table として保存 →GCS へ保存 →
gsutilでマシンへコピー
1 番目は、Jupyter 上でマジックコマンドで Google BQ が実行できて、速度も pandas.rad_gbq よりも高速です
2 番目はそもそも実行結果が巨大な場合で、目安としては1GB以上なら 2 番目の方法を使えば楽です。
1, google-cloud-bigquery をインストールして、Jupyter Notebook のマジックコマンドで Google BQ を実行
pip install --upgrade google-cloud-bigquery[bqstorage,pandas]
magic command を実行
%load_ext google.cloud.bigquery
後は Jupyter Notebook のセルで以下のコマンドを実行すれば、
%%bigquery df --use_bqstorage_api
SELECT
CONCAT(
'https://stackoverflow.com/questions/',
CAST(id as STRING)) as url,
view_count
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE tags like '%google-bigquery%'
ORDER BY view_count DESC
LIMIT 10
df にマジックコマンドで実行した SQL の実行結果が格納されます!
便利ですね
2, BQ 実行 →BigQuery table として保存 →GCS へ保存 → gsutil でマシンへコピー
- BigQuery でクエリを実行、実行結果を BigQuery Table へ保存
- 注)実行結果の容量が巨大なので、保存先は基本的に Big Query Table へ保存するしか選択肢が無い

- BigQuery table から GCS へテーブルを CSV として保存
Big Query table からエクスポート時に、ファイルサイズが大きいとエクスポートできないので、分割が必要です。
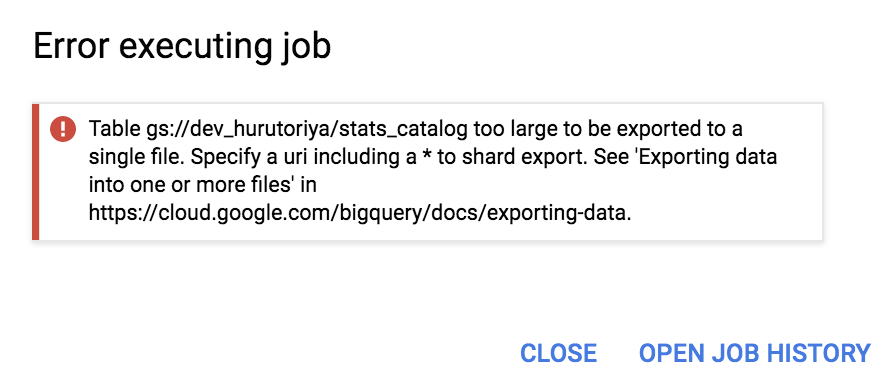
https://cloud.google.com/bigquery/docs/exporting-data
保存ファイル名を file-* のようにワイルドカードを指定すると、自動的にひとつのテーブルを複数ファイルに分割して保存してくれる
gsutil commands で任意のマシンへダウンロードする。
-m オプションを付け足すと並列ダウンロードが始まるので、複数ファイルダウンロードする場合はおすすめです
ストレスレスなデータ分析ライフを!
関連しているかもしれない記事
- Jupyter Notebook上にTensorboard を わずか2行で表示させる
- How to connect the Google Compute Engine via Visual Studio Code
- How to concat image using skimage
- Google Colaboratory で Mecab-ipadic-Neologd を使用可能にする
- Jupyter Notebookの差分を明瞭に確認する事ができるpackage : nbdime
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。