[抄訳] 検索エンジンの達成度と検索チームの成熟度モデル
@rilmayer_jp さんのツイート をきっかけに、検索チームの成熟度モデルの存在を知りました。ありがとうございます!
Eric Pugh さんが、検索エンジンに関する会議で公演した内容で、検索チームがどのように成熟していくかをモデル化しており、それが面白かったので備忘録として残しておく
更新
- 2021/05/13 : 原著者のEric Pugh さんから、抄訳のご快諾いただけました。ありがとうございます
翻訳元資料
- Search Relevance Organizational Maturity Model slide
- Haystack LIVE! 2020 Search Relevance Organizational Maturity Model
検索エンジンのレベル
検索エンジンへの要求をどれだけ満たしているかをピラミッド構造でわかりやすく説明している
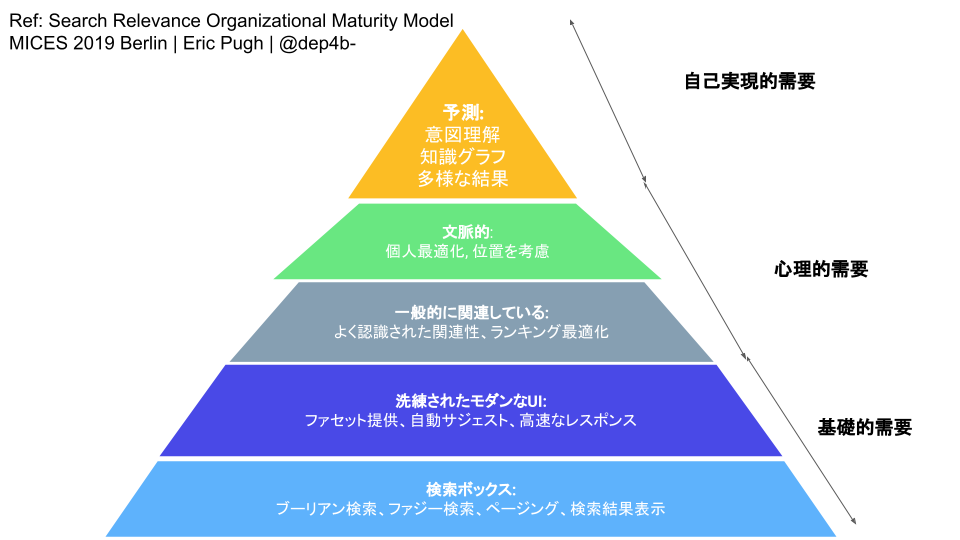
検索チームの成熟度モデル
7 項目の検索チームの評価項目を考え、3 段階で評価を行う
| ビジネス | 顧客の要求の理解 | 検索技術 | 実験駆動 | UX | コンテンツ強化 | データ保有 | |
|---|---|---|---|---|---|---|---|
| 発展 | ステークホルダーがリアルタイム KPI を使用している | データ解析から質的なデータを得ている | カスタムプラグインを作成している | A/B テスト、オフラインテストをサポートしている | 革新的な発見性を提供している(chatbot, 等) | NLP やデータサイエンティストの専任チームが取り組んでいる | 多種多様な、複雑かつ大規模なデータを扱っている |
| 実践 | 不定期にレポートを行っている | いくつかのユーザーテスト、基礎的な分析を行っている | 関連性のための複雑な設定、プラグインの使用をしている | 実験は適用可能だが、A/B テストなどはできない | 発見しやすくするための UI を提供している | 分類学や概念体型の適用をしている | データの複雑度の監視している |
| 基礎 | ビジネスインパクトが測定されていない | クエリログは存在しない、またはユーザーテストを行っていない | 技術スタックを適度に調整している | 検索のテストは手作業で行い、デプロイは低頻度 | 1 ページに 10 個の検索結果がある | 僅かな取り組み(シノニムなど) | とても単純なデータモデル |
感想
ひと目で
- 今の自分達がどの位置にいて
- 何を目指せばいいか
わかる可視化は示唆に富むのでありがたい
関連しているかもしれない記事
- TFXの歴史を振り返りつつ機械学習エンジニアリングを提案する論文「Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)」
- 機械学習システムの信頼性を数値化し、技術的負債を解消する論文「 The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction」
- 機械学習システムの信頼性を数値化する論文「 What’s your ML test score? A rubric for ML production systems」
- [抄訳] Data engineers vs. data scientists
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。