Amazonがeコマース検索を Lucene により、どうスケールさせているか at Berlin Buzzwords 2019
情報検索・検索技術 Advent Calendar 2021 1 日目の記事です。 早めに書き終えたので、カレンダー登録日の 2021/12/01 よりもはやめですが、記事を公開してしまいます。
Berlin Buzzwords はドイツで毎年開催されている OSS を利用した検索、データ処理、データベースに焦点をあてたカンファレンスです。
検索関係のシステムに携わっている場合、毎年面白い内容が目白押しなのでぜひとも見てほしい。
今回は Berlin Buzzwords 2019 で発表された「Amazon では Lucene をどう活用して e コマース検索をスケールさせているか」の講演動画を社内勉強会で紹介するために視聴したので、そのメモを公開する。
E-Commerce search at scale on Apache Lucene
自分の所感などを切り分けるため、自分の意見は IMO ではじめた文にして、メモっています。
Overview
- クエリの p999 latency に対して非常に厳しい制限を行っている
- IMO
- このクエリの p999 latency 定義は、Lucene+(おそらく内製で今も開発している、response を返すための Lucene server?)が返す検索のレスポンスを指していると思われる
- p99.9 latency を SLA として、監視しているのはたしかにとてもシビアな基準だと感じる。
- IMO
- Amazon の query rate はめちゃくちゃピーキー (daily, weekly, yearly)
- Why Lucene?
- Lucene は成熟しており、豊富な検索エンジンの機能が揃っている
- 情熱を持ったコミュニティが存在している
- Uber, Airbnb, Linkedin 全部 Lucene を使っている
- maxscore scoring , Weak AND, Lucene 8.0 での Codec の衝撃
- Lucene design
- 100% Java で書かれている
- on-disc search with small in-memory index
- 巨大な index を扱えるが、小さな RAM で実行可能
- 高い並列性を兼ね揃えたインデキシングと検索機能
- ニアリアルタイムでの検索とインデキシング機能
- Amazon での Lucene 利用例
- ニアリアルタイムでのセグメントレプリケーション (Solr, Elastic Search とは別のレプリケーションの仕組み)
- IMO: 登壇者の Mike さんが Lucene 6.0 をベースにした Near realtime replication が可能なlucene server を公開している。
- yelp が 2021/09 に OSS として、上記の lucene server をベースにした OSS を公開。解説記事も公開してくれている。Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine
- 並行検索 → 複数のスレッドでの並行検索処理が可能 (Lucene で利用可能だが、Solr, ElasticSearch では 2019 年時点では利用不可)
- query time ではなく、index time で join を行いデータの結合を行っている。Lucene 6.0 で追加された BKD-tree を利用した Dimensional points 機能は、多次元空間を効率的に検索することができ、プライムデーで重宝されている。
- また拡張性の高いデザインのおかげでカスタマイズも容易。
- Custom term frequency などもとても便利。当初 Lucene にこの機能は存在しなかったので、我々で機能開発を行い Lucene にこの機能が搭載された。
- 2019 年時点では、Solr, Elastic Search を使っていない。理由としては、Concurrent faceting, multi-phase ranking などの機能は Solr, Elastic Search は当時は利用できなかった。また、現時点で Lucene ベースでのモジュールを多数開発しているのも要因。
- ニアリアルタイムでのセグメントレプリケーション (Solr, Elastic Search とは別のレプリケーションの仕組み)
- Open Source at Amazon
- パフォーマンス課題や小さなバグなどを発見して、それらを解決していった。これはコミュニティみんなが嬉しい。(Solr, Elastic Search にも還元されるのでとても健全な流れだよね)
- 以下の Lucene の機能は Amazon が開発を行い、貢献した
- Custom term frequencies
- Concurrent indexing updates
- Concurrent faceting
- FST direct arc addressing
- Off-heaps FSTs
Service architecture
- Near-real-time replicaiton
- Black Friday や Prime day などの爆発的にアクセスが増加するイベントなどに対応するために作成
- Solr, Elastic Search で提供される document level レプリケーションでは限界がある
- Service architecture
- AWS で構築
- ECS コンテナでインデクサー、サーチャーが稼働している
- Kinesis, DynamoDB からカタログが更新される
- ニアリアルタイムで、S3 にインデックスは保存される
- インデックスはソフトウェアが更新されるたびに、全て再構築される
- 人為的なクエリでサービスを暖機運転
- Service system design
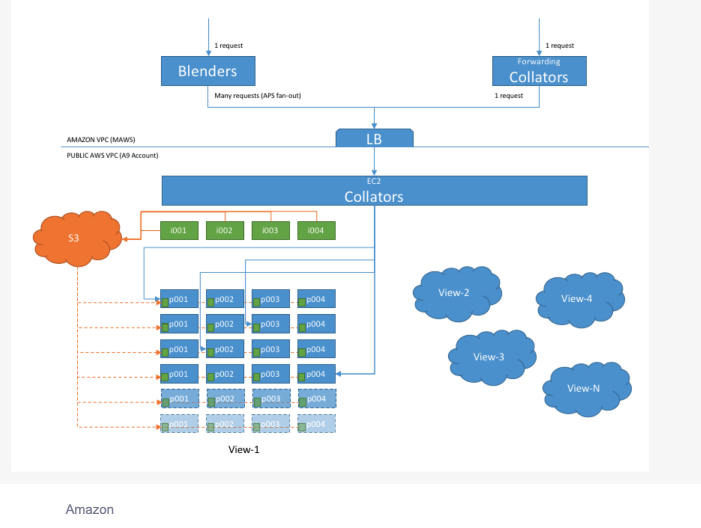
- リクエストが来た際に、Collators がリクエストをさばいて、適切な view に割り振る。
- Index(i001, i002, …) は S3 にリアルタイムで保存され、service はその index を読み込んで検索を行って、レスポンスを返す。
- Searching a segmented index
- Lucene には検索インデックスが必要で、分割型のアーキテクチャとなっている
- merge して結果を返す
- Searching a segmented index concurrently
- index は統計的に商品品質によりソート済
- この機能はシャードが巨大化している我々にとってレイテンシーを抑えるために非常に有用な機能
- p999 latency figure
- 青色のグラフの挙動は、Lucene の分割型アーキテクチャによって発生しており、並行検索がどのように優位性をもっているのかを説明する。縦軸は latency
- 緑色のグラフは、どれくらいのサイズのセグメントがレプリカにコピーされているかを示している。縦軸は GB。
- 大きなセグメントがマージされたときにスパイクが発生する
- 通常は、小さなインデックスがマージされて大きなインデックスになることは良いことである、なぜならたくさんのファイルを開く必要がなくなるし、すべてのセグメントを探索しなくても良くなる。
- だが、Amazon の場合は、並行検索を行っているので、大きなセグメントが存在すると逆にレイテンシー増加の要因となる。なぜならセグメントの数が減少すると、検索の並行性も失われるため。例えば、10 のセグメントがあった場合、10 スレッドで並行検索を行えるが、一つのセグメントになってしまった場合、1 スレッドでの検索しかできなくなる。
- Mike さんは、例えば一つのセグメントに対して、複数スレッドで並行検索できるようになれば、この問題への改善が見込めると考えているらしい。
- 大きなセグメントがマージされたときにスパイクが発生する
- セグメントインデックスに対して、並行検索が可能になったことで、大きなセグメントを取り扱うことを避けれるようになった
Performance mesurement
- Bemchmarking
- Lucene nightly benchmarks
- 上記と同じような方法で、各種クエリのパフォーマンスを常に測定している。
- perfoamance regression の検知は困難
- performance だけではなく、検索性能も自動的に評価
- Lucene nightly benchmarks
- Concurrent refresh
- Lucene は、並行リフレッシュのために、インデックスサイドのアプリケーションのスレッドを借りるという問題があった
- 解決方法として、インデキシングが行われていないときのみ並行リフレッシュを行う機能を開発
- Lucene は、並行リフレッシュのために、インデックスサイドのアプリケーションのスレッドを借りるという問題があった
- Gathering metrics using Lucene’s abstractions
- Lucene の抽象化機能を使って、各指標を容易にモニタリング可能に
- Garbate correction is too hard
- IMO: ここらへんは知識が足りず理解できなかったので、後から勉強
Analysis challanges
- Context sensitive analysis
- plane は何を意味する?
- おもちゃの airplane?
plane ←→ airplaneの同義語 - synonym 拡張をを index time のみで行う
- Numbers a special
- Toy for 3 year old というクエリには、 2-4 歳対象という文章は対象になる
- 1500ml は 1.5 litters とマッチするべき
- 1,100、1100、1.100 は一緒で、1/100、1:100 とは違う
- 標準的な tokenizer の後に上記のハンドリングをするのは難しい
- 句読点の取り扱いには注意
- WordDelimiterGraphFiltter
- Lucene docs
- 英語と数字の分割など細かい前処理が可能になる
- e.g. “SD500” → “SD”, “500”
- 英語と数字の分割など細かい前処理が可能になる
- 機械学習はこの問題は解決可能だが、検索ではこのような機能もやはりまだ必要である。
- IMO: Lucene の機能を使って解決可能なら、たしかにできる限り機械学習を使いたくない気持ちは非常に共感できる。ここまでレイテンシーの制約が厳しいなら増加要因は可能な限り抑えたい…
- Lucene docs
Query optimization
- Indexed Queries
- 多くのクエリは共通のフィルターを使っている。
- 大元のインデックスに対して、共通で使われているフィルターを適用した結果を、インデキシングしてる? (post-processing index)。
- single term に置き換えて、パフォーマンスをチューニング
- Factoring queries
- Boolean query
- FP growth algorithm
- Query 最適化のおかげで、 +30% redline QPS が増加。p99 latency は 81ms から 54ms へ。
- IMO: P99 のレイテンシー公開して良いだろうか…??? (p99.9 は公開していなかったので気になる)
- Indexing tuples
- multi stage search を single stage に圧縮している
- IMO: ここらへんの最適化は、Lucene の検索の仕組みをもっと理解しないとどうやって実現しているかまだ深く理解できない
- Lighting deals using dimensional points
- 当初は mike さんにより、地理検索などを目的として作られた機能。だが、地理検索には使用せず、Amazon での lighting deal に三次元データ(start time, end time, id) での三次元検索にこの dimensional points 機能を使ってる。
- IMO: by @takuya-a さん - 社内で発表した際に、なぜ start-time, end-time の 2 次元ではなく、id を入れた 3 次元にした検索にしたのかという質問に対する完璧な @takuya-a さんの推測
ID も空間インデックスに含めることで、パフォーマンスを上げているのだとおもいます。ID が別フィールドだと、そっちのインデックスも検索して、空間インデックスの検索結果とマージして、って処理が後段で必要になるのですが、最初から ID も含めておくと BKD-tree の検索で全部処理できちゃうので。同じ期間で別の ID をもつセール対象商品がヒットしないので最初の段階でかなり絞り込めるようになるのだと思います
- BKD tree の解説は @pon さんの記事がわかりやすいです
Multi phase ranking
- Ranking
- Machine Leraning models
- Multi phase ranking
- Prorated early termination
- IMO: スコアリングの知識が欠如しているのでメモだけ
- Summary
- Amazon で検索してるときには Lucene が使われているよ 100%ではないけども
Question
- Q. indexing synonym を行っていると言っていたが、例えば query timing で synonym を扱えれば、検索者の文脈などを考慮した同義語を扱えるのではないのだろうか?
- A. indexing synonym は主に効率性を重視した意思決定であり、基本的にトレードオフの関係となっている。Query rewrite なども行っているが、今回のトークは主に検索エンジンなので優先順的に Query Understanding 関係の話はしていません。
Reference
Lucene に詳しい同僚からは、Lucene に興味あるならこの本がおすすめと言われので読んでおきたい。 ちなみに著者は、この講演者のうちの一人である Mike McCandless さん… (14 年間 Lucene の開発をしている!!)
余談ですが、この人のことを同僚が、
Lucene 界隈では神として知られていますね
と言っていて、笑った w
情報検索・検索技術 Advent Calendar 2021 の次の記事は @sz_dr さんで 4 日目を担当してくれます!
関連しているかもしれない記事
- eコマースの検索と推薦についてのサーベイ論文である 'Challenges and research opportunities in eCommerce search and recommendations' を社内勉強会で発表した
- [抄訳] 検索エンジンの達成度と検索チームの成熟度モデル
- クエリ分類(Query Classification) について社内の勉強会で話してきた
- TFXの歴史を振り返りつつ機械学習エンジニアリングを提案する論文「Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)」
- 機械学習システムの信頼性を数値化し、技術的負債を解消する論文「 The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction」
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。