Amazon検索ランキングの奥深さ at MLconf SF 2016
1 日遅れてしまいましたが、情報検索・検索技術 Advent Calendar 2021 25 日目の記事です。
ついにアドベントカレンダー最終日を迎えました!
今年はまだ検索領域のアドベントカレンダーが作られていないからということで、勢いで情報検索・検索技術 Advent Calendar 2021を作りましたが、多くの方に投稿に協力していただきありがとうございました。
社内勉強会の発表でネタを探しており、2016 年と少し昔の情報ですが、Amazon の製品検索において、どのようにランキングを行っているかの公演動画が非常に面白かったので、勉強がてら残したメモを記事として公開します。
今回の口頭発表は MLconf という開発者会議(非学会・非アカデミック)で発表されています。 自分が知る限り、MLconf は機械学習黎明期から高品質な発表が継続されて発信されており、非常に素晴らしいカンファレンスの一つ。 国際会議には投稿されていないが、実応用の観点からしてとても学びの多い発表がとても多いです。 機械学習の応用を考えている場合、世界の最先端事例を知ることができるので非常におすすめです。
Referemces
Sorokina, D., & Cantu-Paz, E. (2016, July). Amazon search: The joy of ranking products. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval (pp. 459-460).
メモ
自分の私的な意見は NOTE: で書いておきます。
Search Ranking Models
- 1Model = 1 context: 一つのモデルで一つの国の 1 カテゴリをサポート
- 日本の書籍カテゴリで 1 モデル、フランスの家電領域で更に一つのモデル
- モデルの軽量化と精度向上のためにコンテキストごとの最適化されたモデル作成を許している
- 現在、100 以上の機械学習モデルを利用している
- GBDT ベースのモデルや、pairwise ランキングモデルなど
- モデルはだいたい 200 以上の tree で構成されている
- 150 種類以上の特徴量が利用可能だが、それぞれのモデルが利用しているのは 30 以下
- 映画では、
days_since_releaseがとても重要だが、他のカテゴリではそうではない
- 映画では、
Training Labels
- 学習データを顧客の行動ログから作成する
- 利用可能なポジティブラベルとして
- クリックされたか?
- カートに入れられたか?
- 購入されたか?
- 消費されたか?
- ネガティブなラベルとしては
- 無視された結果
- 検索結果には表示されたが、何も行動が起こされていない製品
- 検索結果から、そもそも表示されなかったページからランダムサンプリング
- ページネーションにより表示されなかったページからサンプリングを行う(slide が消えていて見えなかったので論文から補足)。
NOTE:アルゴリズムバイアスを加速させるような気もした。表示されなかったが良い商品をどうやって救い出すかも大事な観点。
- ページネーションにより表示されなかったページからサンプリングを行う(slide が消えていて見えなかったので論文から補足)。
- 無視された結果
Mixing Click and Purchase Targets
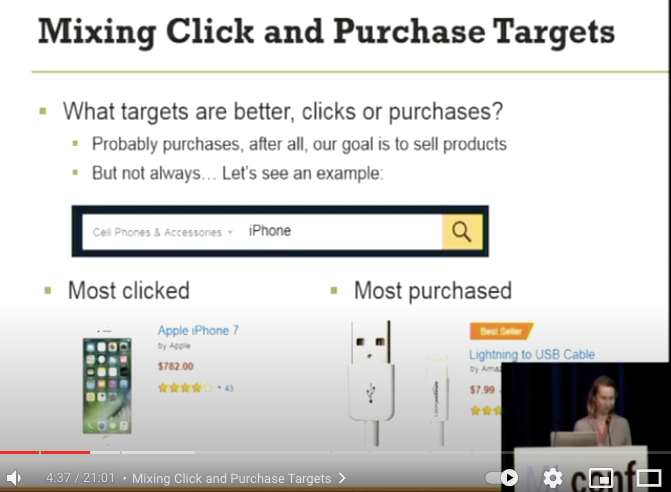
- 何を目的変数とすべきか? クリックなのか、それとも購入か?
- おそらく購入されたかどうかでしょう、なぜなら我々の最終目標は製品を売ることなので
- しかし、いつでも購入がゴールというわけではない… 例をお見せします
- Keyword: iPhone
- 最もクリックされたもの
- iPhone7。700 ドル以上もするのでクリックはされますが購入されません
- 最も購入されたもの
- 一番購入されたものは何でしょうか? 最安価な iPhone モデルでしょうか?
- 正解は… 8 ドルの Lightning to USB Cable です…!
- もし購入されたことのみを目的変数にしてしまった場合、iPhone と検索して Lightning Cable しか表示されなくなり、検索機能が壊れてしまいます。
- 最もクリックされたもの
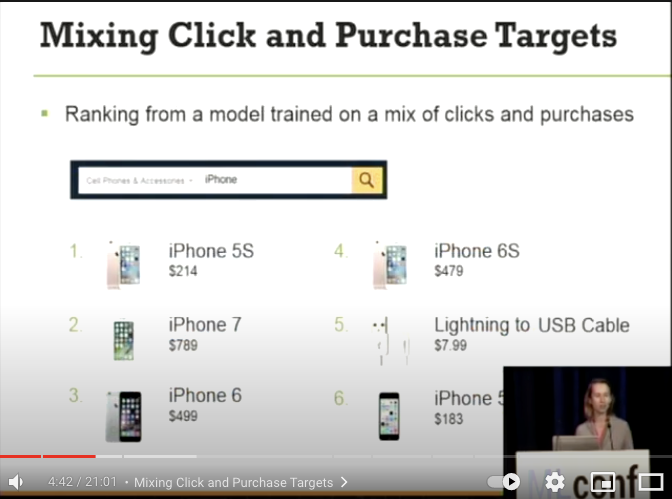
- これがクリックと購入を混在させたモデルの検索結果になります
- iPhone 5S は iPhone モデルシリーズで最も安く最も購入され、その後に 最もクリックされる iPhone7 その後に Lightning Cable が表示されています
- これによって、異なる顧客の意図を汲み取った検索結果を提供できるようになりました
Fast Feature Evaluation
- 2 段階の特徴量選択
150→50: ランダムな特徴集合よりも良い結果を出した特徴を選択
50→20: 後方除去、前方選択により枝刈り
- ツリーのアンサンブルにおける特徴量のスコアリング
- 全てのツリーは特徴量のスコアリングアルゴリズムを持っている
- 課題点として 2 値と連続値の特徴量は比較ができない
is_prime_benefitは Amazon Video で最も重要な特徴量である- しかし、特徴量選択では、いつもランダムな連続値の特徴量にスコアは低くなっている。何故?
- アンサンブルツリーはランダムな分割を多く実行する
- 単一のツリーの分散は最終段階では平均化される
- 連続値の特徴量は更に可能な分割を提供する
- よって、ランダムな分割で多く選ばれる
- それによりスコアリングが高くなる
- それらを避けるには正規化の処理が重要になる
- 異なる一様分布の値から 6 つのランダムな特徴量を作成・追加を行い、ビデオ領域で実験を行った
- 本来なら全ては意味のない特徴量なので、全ては同一の低いスコアリングがされるべきである

- しかし実験の結果、乱数の値に伴って対数的にスコアリングが変化していることがわかった
- 正規化された特徴量スコアでのバギングツリーを我々は利用している
- 上記の手法は OSS として公開しています
- 上記の手法を適用後、スコアリングが最も高くなったのは
is_prime_benefit特徴量になりました - All Product Search
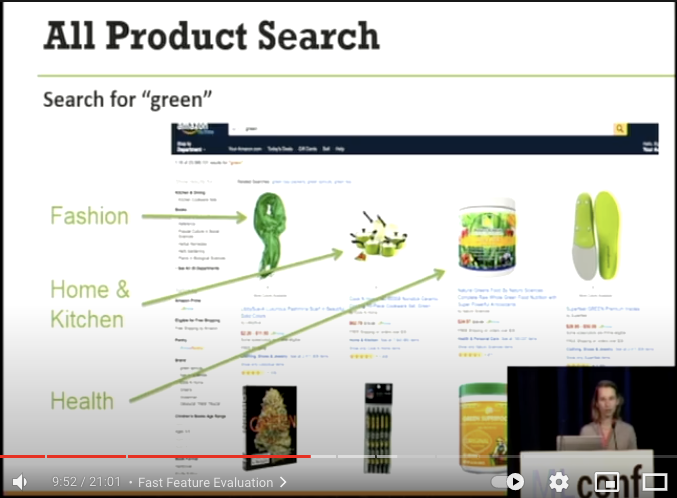
greenと検索を行うと以下の結果が出てくる
Components of the Blending Score
- Fashion, Home&Kichen, Health カテゴリの商品が出てきます。どのように各カテゴリのスコアを計算しているのか?
- Query Category score
- 一般的なクエリ: クリック数、カートに追加したか、購入したか?
- 稀なクエリ: クエリの trigrams , bigrams, unigrams でのクリック数
- Hunger score: 飢えのスコア(動的なスコア)
- 重要なカテゴリはこの Hunger Score が高くなりやすく設定
- 他のカテゴリが選択されるたび Hunger Score が高くなり、それがカテゴリ選出のスコアリングでは重要になる
- In-category relevance score for each product
- relevency が高い製品は選ばれやすくなる
- このスコアは異なるカテゴリ間でも比較可能なものにしなければならない
- All Product Search - Blending
greenというキーワードに対しての Blending Score の具体例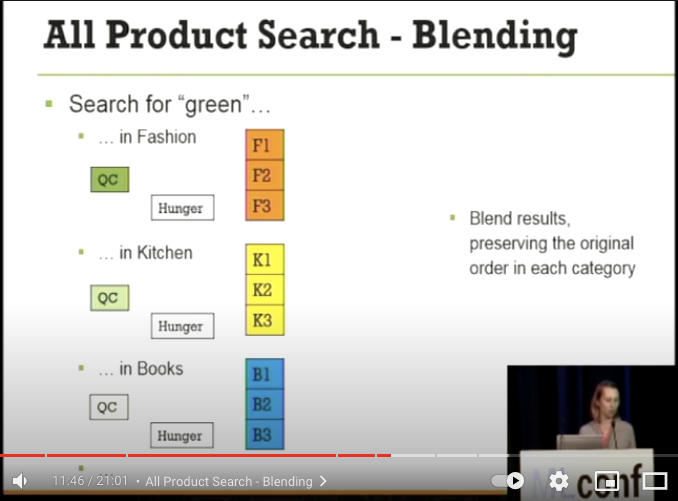
- Fashion, Kitchen, Books カテゴリの中からどのように各カテゴリの商品が選出されるか?
- 各カテゴリの Query Score は、Fashion, Kitchen, Books の順番に高い
- 初期の全ての Hunger score は 0。白 → 灰色 → 黒と Hunger score が高くなる
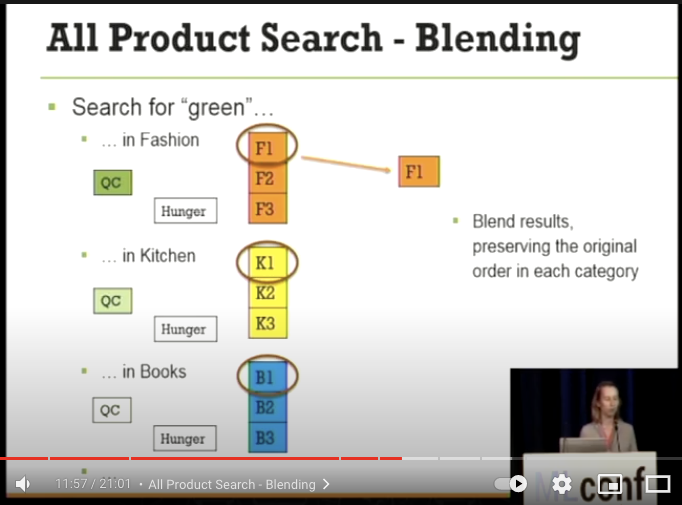
- まずはじめに、各カテゴリの Top1 製品の F1, K1, B1 を比較して、F1 が QueryScore に基づき最もスコアが高い F1 が選出される。

- Fashion が選択されたので、Kitchen と Books の Hunger Score が高くなり、Hunger Score がより高い K1 が選出
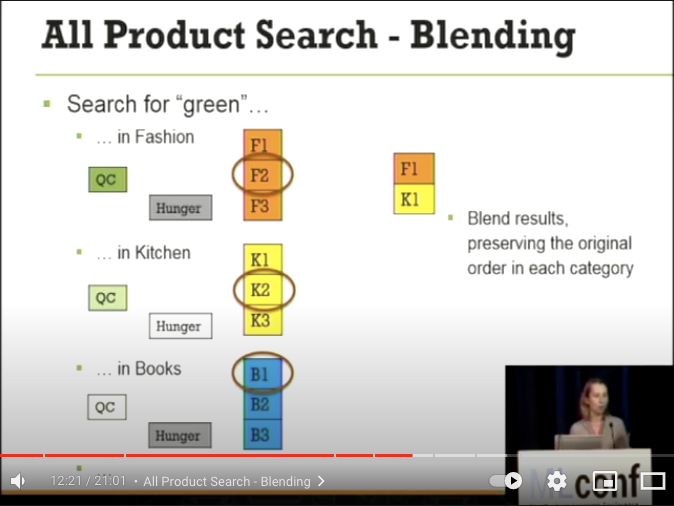
- Fashion カテゴリは重要なので Hunger Score がより早く高くなりやすい。Query Score と合わせて、三番目には F2 が選出
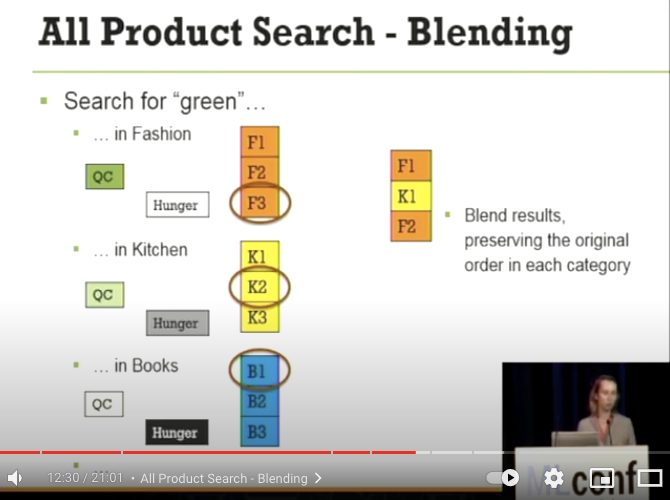
- Books カテゴリの Hunger Score がとても高くなっているので、ついに B1 が 4 番目には選出される
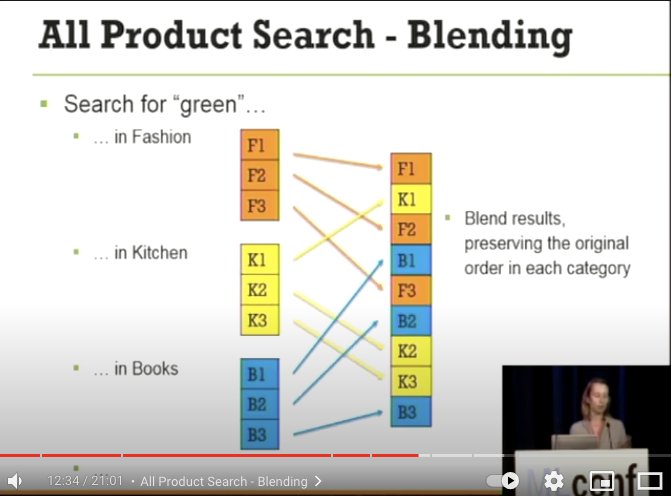
- 上記の考えで各カテゴリ間でスコアを比較して検索結果に混ぜていく
Match Set
- Match set は、クエリに対して返された結果の集合
- Match set は 2 つのパターンの製品を含む
- 例:
zootopiaというクエリで、70538 個の mache set が返ってきた - Textual matches
- クエリに対して、Query understanding 後に Product description とマッチした製品
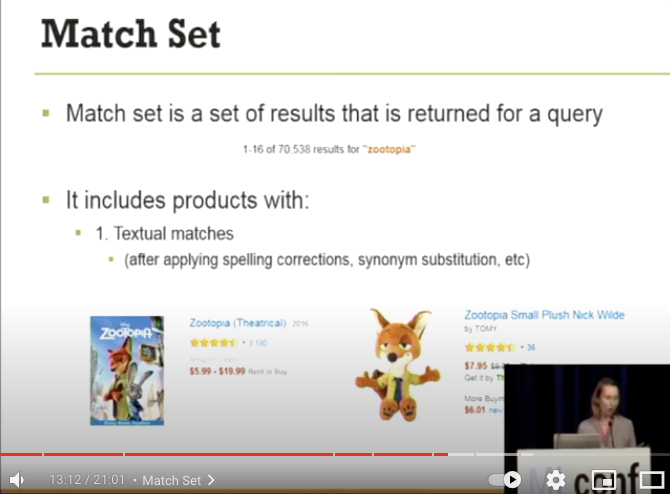
- Behavioral matches
- そのクエリで検索後に、クリック、カートに追加、購入した商品の集合
- 今回の場合は、
zootopiaで検索後にクリック、カートに追加、購入した製品を指す。 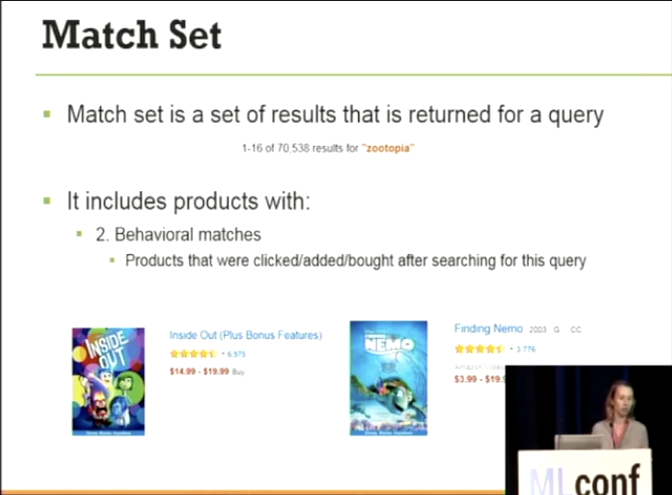
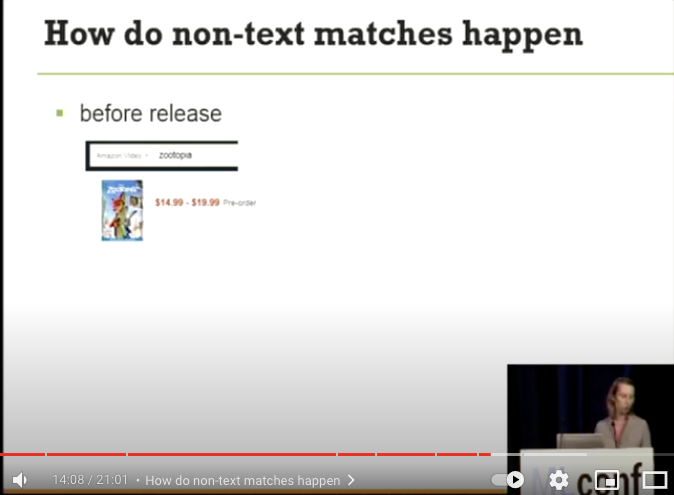
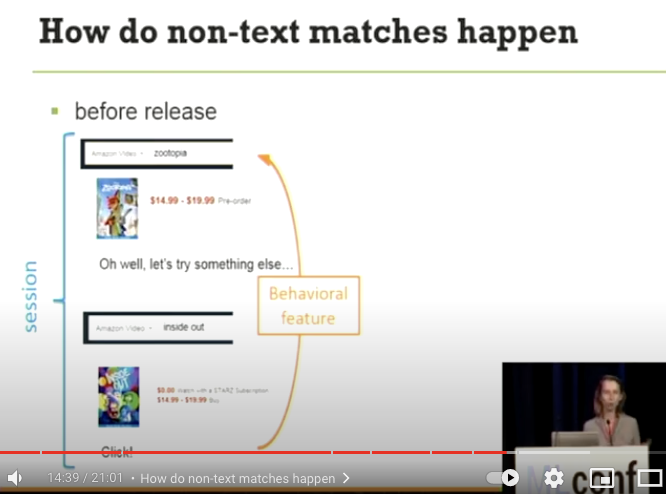
- どのように非 text-match が発生するか
zootopiaで検索
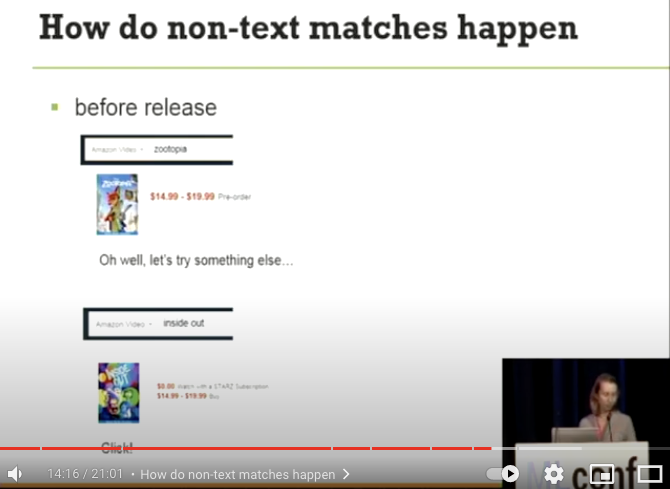
- その後クリックはせずに、
inside outで検索を行い製品をクリック
- その後クリックはせずに、
- この 1-2 を同一セッションとして Behaivioral feature として扱う
- 3 の特徴量を取り入れることで、非 text-match の製品を match set に取り込む
- 例:

Cold Start
- 新しい Harry Porrer の書籍が利用可能になります!
- 私達はこの書籍がベストセラーになることを知っていますが…
- Behaivioral feature がまだ存在しない
- どれくらいクリックされるかは我々は知らない
- 古い書籍は多くの signal を持っているので、新しい書籍は下のランクに位置づけられる
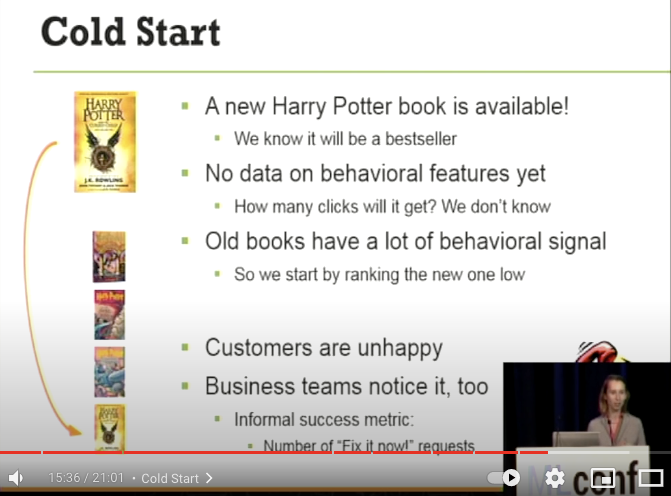
- 求めている書籍が検索結果の下にあるのは顧客は不幸です。
- Business チームもこの異常事態を伝えてきます
- ジョークですが、非公式の指標として、「今すぐこれを直してください」の要求の数が低ければ低いほどよいです
- Day 0: 全ての behaivioral features は 0
- 時間特徴量がここでは助けになる(新製品にたいして Boost を行い、ランクを上にする)
- ここで顧客が製品に対してクリックを行い、signal が溜まっていきます
- Day 1: Behaivioral features はまだ更新されていない
- クリック情報を持っているが、検索エンジンにはまだ反映されていない
- 強靭なインフラが、新製品に対して signal の蓄積を迅速に反映させていく
- Day 7: Behavioral features はゆっくりと蓄積されていくようになる。
- signal が十分にたまり、新製品としての時間特徴量の boost はここでは取り扱われなくなる
- ここから、適用されるスコアリングの公式が固定される
- 殆どの人が Cold start は Day 0 に対してのみ考慮するが、Day0-7 まで考える必要がある
- 時間経過にともなって、スコアリングをどう行っているか
- 理解が浅いのでここは省略します。だれか解説してくれると嬉しい
Non relevence Sort
- big keyward では match set がとても巨大になります
- 例:
tvというキーワードに対して家電カテゴリで 102,4635 の結果が存在する。 - relevance sort は適切な検索結果が返ってくるが…
- Customer review での平均でソートを行うと
- relevance がぐちゃぐちゃになってしまう。もちろんカスタマーレビューはありがたい機能ですが…
- relevance がぐちゃぐちゃになってしまう。もちろんカスタマーレビューはありがたい機能ですが…
- 改善方法
tvというキーワードに対して 500 の製品タイプが Amazon catalog で存在する- {query, product type} のペアでスコアを計算する
- どの product type が特定のクエリにおいて最もクリック、カートに追加、購入されたか
- 特定のキーワードでフィルターを行い、指定の product type の製品のみを表示するにした
- keyboard→ キーボード製品
- USB→ フラッシュメモリ、ネットワークデバイス、入力デバイス
- TV→ テレビタイプ
- これによって Customer review の平均でソートを行っても relevance が保たれるようになった
tvで customer review の平均で sort を行った際に 991 個の製品のみが表示され、relevance が向上した
- 例:

蛇足
この論文は、過去に読んだサーベイ論文で面白そうとメモしておいたのがきっかけで知ることができた。サーベイ論文の紹介記事はこちら
関連しているかもしれない記事
- Amazonがeコマース検索を Lucene により、どうスケールさせているか at Berlin Buzzwords 2019
- クエリ分類(Query Classification) について社内の勉強会で話してきた
- eコマースの検索と推薦についてのサーベイ論文である 'Challenges and research opportunities in eCommerce search and recommendations' を社内勉強会で発表した
- [抄訳] 検索エンジンの達成度と検索チームの成熟度モデル
- TFXの歴史を振り返りつつ機械学習エンジニアリングを提案する論文「Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)」
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。