OSS の Google BigQuery UDF `bqutil.fn` を使えば UDF の独自実装を置き換えられるかもしれない
TL;DR;
UDF を独自実装する前に、bqutil.fnを眺めておくと車輪の再発明が回避できるかも
背景
SQL は、特定の処理を行う際にデータの型が同一でないとエラーが発生しますが、もとのスキーマを紹介するよりももっとお手軽にカラムの型を確認したいときがありませんか?
例えば、出力結果を見ただけでは、12345 が STRING なのか INT64 なのか判別不可能ですよね。(もし判別可能な方法知っている人いたら教えて下さい…)
GCP による OSS UDF の bqutil.fn
なのでお手軽に BigQuery の結果の型を確認したい時になにか良い方法がないかなと調べていたら、OSS でbqutil.fnという UDF が GCP から提供されていた。
例えば型の確認の場合、以下の ユーザー定義関数(UDF) はどの GCP プロジェクトから実行しても実行可能
bqutil.fn.typeof()
このbqutil.fn はbigquery-utils/udfs/community/のディレクトリに格納されている UDF がbqutil という GCP プロジェクトのfn データセットに同期されているので、どの GCP プロジェクトの Google BigQuery から実行しても bqutil.fn.typeof()を実行可能にしているらしい。
頭良い
This directory contains community contributed user-defined functions to extend BigQuery for more specialized usage patterns. Each UDF within this directory will be automatically synchronized to the bqutil project within the fn dataset for reference in queries.
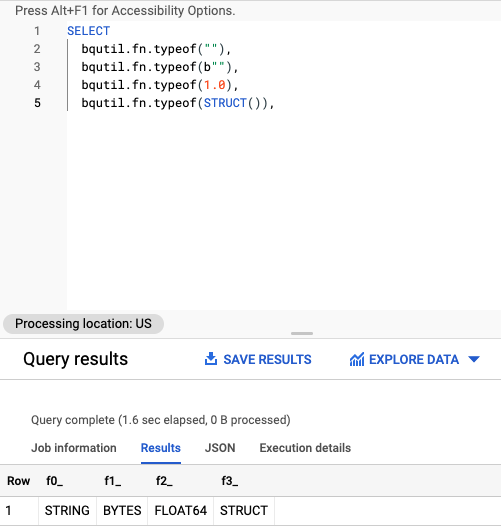
実際に以下のクエリを Google BigQuery で実行すると
SELECT
bqutil.fn.typeof(""),
bqutil.fn.typeof(b""),
bqutil.fn.typeof(1.0),
bqutil.fn.typeof(STRUCT()),
STRING
BYTES
FLOAT64
STRUCT
の結果が出力され、各カラムのデータの型を確認できる。
便利!
これで置き換え可能な UDF は置き換えればメンテンスしないといけない UDF が削減されて嬉しいですね
bqutil.fn.typeof() の UDF の実態としては
bigquery-utils/udfs/community/typeof.sqlxが参照されて実行されている。
他にも
- URL の key を抽出できるbqutil.fn.url_keys()
- ランダムな値を出力できるbqutil.fn.url_keys()
など、自前で正規表現で頑張って書いているけど実際は OSS の UDF として公開されているケースも多々ありそうなかゆいところに手が届く UDF が多数公開されていた。
変わり種としては、 StatsLib: Statistical UDFsという統計的な処理を行う UDF も公開されていた。
線形回帰や p 値の計算ができる UDF も公開されており、面白い
References
関連しているかもしれない記事
- 遅すぎる `pandas.read_gbq` を使わずに、Google BigQueryから高速にデータを読み込む
- Standard SQLのCOALESCEで、時間経過によってカラム名が変化したデータを柔軟に抽出する
- Dataflow template を使って Google Cloud Pub/Sub の中身を簡単に確認する
- CloudComposer のDAGをCircleCIで更新する
- GCPのCloud Composer のDAGを素早く・簡単にデバッグする
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。