Amazon の製品検索で使われるロバストなキャッシュ手法の論文「ROSE: Robust Caches for Amazon Product Search」
Web 検索とデータマイニングのトップカンファレンス WSDM2022 のワークショップで The First International Workshop on INTERACTIVE AND SCALABLE INFORMATION RETRIEVAL METHODS FOR ECOMMERCE (ISIR-ecom) が先日開催された。
テーマは e コマース上での検索において
- 検索システムのスケーラビリティ
- どうやって適合性(Relevancy)をシステムで改善したか
- システムの改善
についてをテーマにした検索エンジニアなら垂涎もののワークショップとなっている。
同様の検索システムや実応用に注目したワークショップでは、以下のようなワークショップがある。
- SIGIR Workshop On eCommerce 2017 年から毎年開催。累計 5 回開催
- International Workshop on Industrial Recommendation Systems 2020 年から開催。累計二回
歴史としては、 SIGIR ecom が長く、これだけの期間継続開催してくれているのはありがたい限り。
機械学習系の国際会議でも手法ではなく、どう現実世界に適用したかに注目したワークショップが益々誕生しており非常に良い流れ。
ACCEPTED PAPERS は 5 本あり、
- Amazon: 2
- eBay: 1
- The Home depot: 2
と企業関係者による論文が 100%となっている。
https://github.com/ISIR-eCom/ISIR-eCom.github.io/tree/main/papers 最後の PDF 番号が 9 なので、最低でも 9 本の投稿はあった模様。
素晴らしいワークショップなので、来年も是非継続して開催してほしい。
すべての採択論文が面白そうだったが、今回は Amazon Search が公開した Chen Luo らの「ROSE: Robust Caches for Amazon Product Search」を紹介する。
私的な感想やコメントは NOTE: で始める文章で書き留めています。
一言で説明
クエリの書き換え(誤植を修正する)と深層学習モデルの結果のキャッシュを同時に行えるキャッシュシステム ROSE を提案して、検索システムの応答速度と検索性能を改善。
Citation
ROSE: Robust Caches for Amazon Product Search, Chen Luo, Vihan Lakshman, Anshumali Shrivastava, Tianyu Cao, Sreyashi Nag, Rahul Goutam, Hanqing Lu, Yiwei Song and Bing Yin, Proceedings of the International Workshop on Interactive and Scalable Information Retrieval methods for eCommerce (ISIR-eCom), 2022.
概要
Amazon Search のような商品検索エンジンはしばしばキャッシュを利用する。 キャッシュによって Amazon の製品検索での顧客体験を向上させることができる。 顧客体験だけではなく、検索システムのレイテンシも大幅に向上する。
だが、検索トラフィックが増大しキャッシュサイズが大きくなりすぎると検索システム全体のパフォーマンスが劣化してしまう。 また、誤字やスペルミス、現実世界で見られる冗長な表現のクエリは不必要なキャッシュミスを引き起こし、キャッシュの効率性を低下させる。
「RObuSt cachE(ROSE)」はロックアップコストはそのままにスペルミスや誤字を許容可能なキャッシュシステムを提案。 ROSE はあらゆるクエリの意図、誤字、文法ミスに対して理論的な頑健性が保証されている。 現実世界のデータセットにより ROSE を評価して、有効性と効率は検証を行った。 ROSE はすでに Amazon の検索エンジンにデプロイされており、既存のキャッシュシステムと比較しても大きくビジネス指標を改善している。
INTRODUCTION
検索エンジンで大事な2つのパフォーマンス指標
- 顧客化からのリクエストに対するレスポンスタイム
- 顧客の意図に適合した高品質な検索結果
現代的な製品検索エンジンでは通常、計算不可が高い機械学習モデルが多く使われている。
NOTE: [1, 8, 9, 13, 20, 28, 29, 31] の参考文献が、検索改善のための機械学習適用の文献リストとして有用そうだった。
[18] relevance matching models。[2] ranking models。[27] query annotation models。
レイテンシの制限とコストの考慮により、実際の製品検索エンジンでは、計算コストが高い深層学習モデルをサービングして検索トラフィック全体を処理することは禁止されている[14]。そのため、深層学習モデルの推論結果をサービングする代わりに、より実践的な解決方法として頻繁にリクエストがくるクエリに対して深層学習モデルの結果をキャッシュしておく。
従来のキャッシュは以下のようなトレードオフの問題がある
キャッシュミス率とキャッシュサイズの関係: 小さいキャッシュサイズでは、高いキャッシュミス率となる。一方で製品検索エンジンの規模で頻繁に検索されるクエリに対してキャッシュを作成したとして異常にキャッシュサイズが大きくなってしまう。また、 ”Nike shoes”, “Nike shoe”, and “Nike’s shoe” のような同じ意図のクエリだが、形態素的には異なるそれらのクエリはすべて別のキャッシュとしてキャッシュされてしまう。
また、 Query rewrite for null and low search results in eCommerce. In eCOM@ SIGIR. [24]でも示されている通り、検索結果の品質を下げている要因のほとんどが 誤植)。
これらの検索品質が低いクエリは、高品質な検索結果を提供する頻繁に検索されるクエリと語彙的(Lexically) または意味的 (semantically)に似ている。
よって、もし我々が低品質な検索結果を提供する誤植のクエリを、同じ意図を持つクエリへキャッシングの仕組みにより紐付ける(map する)ことができたなら、検索品質を向上させることができる。また、レイテンシも大幅に向上させ、キャッシュサイズも大幅に抑えることができる。
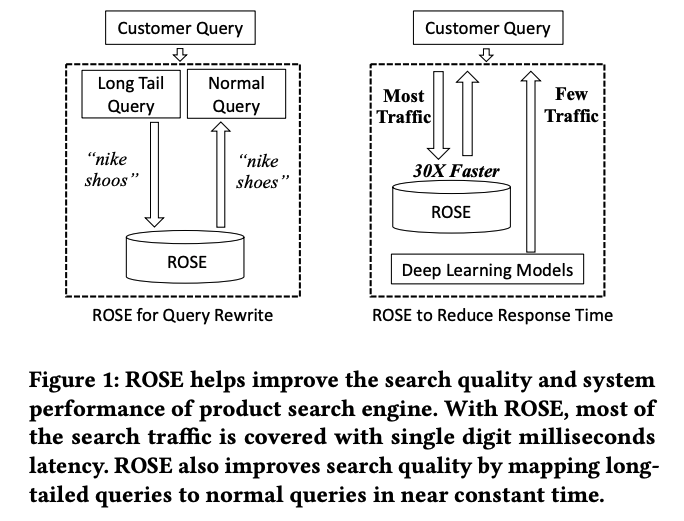
Fig. 1: ROSE は検索品質と検索速度を向上させる
- キャッシュによるクエリの書き換え(query rewrite)によって検索品質の向上
- ROSE が大半の通信をカバーすることで、検索速度の向上。キャッシュヒットしないような少数派のクエリに対しては、深層学習モデルによって直接サービングを行う。
3つの貢献点
- 運用システム: 製品検索のクエリをキャッシュするための、ROSE を提案。定数時間と定数メモリで web 検索規模のデータのインデックスを作成してルックアップを実行可能
- 技術的革新: local-sensitive hashing, reservoir sampling, count-based k-selection など複数の強力な乱択アルゴリズム技術を組み合わせたシステムを開発。これにより、定数時間での検索を維持しながら ROSE を大規模なクエリセットにスケールアップが可能になった。
- 現実世界での効果: Amazon 検索に ROSE をデプロイしており、既存手法と比べてパフォーマンス、ビジネス指標ともに改善された。
BACKGROUND AND RELATED WORK
Robust Cashes
検索エンジンやデータベースなど応答速度がクリティカルなアプリケーションではキャッシュはとても有効なアプローチ。 hash-tables と Bloom fillters によって、キャッシュは完全一致によるキャッシュなどが考案されている[16]。 だが完全一致に注目しているため誤植に弱く従来の完全一致キャッシュでは、キャッシュヒット率が低くなってしまう。 逆に従来の単語のゆらぎに頑健(ロバスト)なキャッシュ手法は、キャッシュの文字列の類似距離を計算するコストが非常に高かった。
定数時間と定数メモリで実行可能なロバストなキャッシュの仕組みである「ROSE」提案する。
Locality-Sensitive Hasing
LSH の解説資料はこちらの資料がわかりやすかった。
他にも LSH の発展形として Jaccard 類似度を使った LSH である Minwise Hasing(MinHash) や Densified One Permutation Hashing (DOPH) なども紹介されていた。
NOTE: 時間が足りないので一旦深い解説は割愛する。ここらへんは自分の知識が浅い部分なのでちゃんと理解しておきたい。
問題の定式化
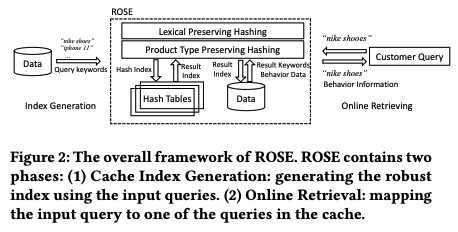
ROSE のフレームワーク解説
- クエリキーワードからロバストなキャッシュインデックス生成
- オンライン検索: 入力されたクエリをキャッシュ上の別のクエリにマッピングする
ROSE: ROBUST CACHE VIA RANDOMIZED HASHING
ROSE Index Generation
ROSE のインデックス生成時には2つの条件
- 誤植や意味的に同じだが異なるクエリでもロバストな性能のために、キャッシュのルックアップ時に入力クエリの類似度を計算してマップする
- 大規模な製品検索エンジンなので、キャッシュサイズはクエリの量に応じてスケーリングすることを回避する必要がある
LSH のアプローチでは、データの規模に対して線形にハッシュテーブルのサイズが増加する課題がある[23]。 この課題は web 規模のデータを扱うと容易にメモリが爆発を引き起こす。 その課題を解決するために reservoir sampling algorithm[25] を使って解決している。
reservoir sampling algorithm の日本語の解説記事はこちら
大量のテキストからランダムに少数の行を抽出したい - Reservoir Sampling
NOTE: ここ完全に理解不足なので言葉だけ理解。
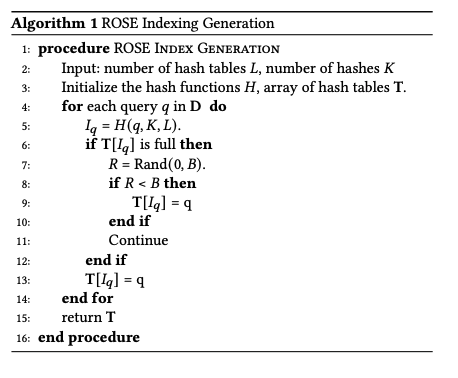
B はハッシュテーブルハッシュテーブルのバケットの数、Iq はハッシュ関数により生成されたインデックス。 Rand(0,B)は-から B までの乱数を生成する関数。
ROSE Online Retrieval
クエリが入力された際に、ROSE は Count-based 𝑘-selection [15]という手法を使って、計算コストの高い 2 点間の類似度(pairwise-similarity)の計算を避けている。
ROSE のオンライン検索が定数時間で終わることは、3.5 Theoretical Analysisにて解説。
Lexical Preserving Hashing
Lexical Preserving Hashing は語彙的な類似度を保持したハッシュ手法を指す。 クエリ間の類似度は Jacard 類似度を使って計算する。(つまるところ minhash?) 実際に計算する際には DOPS を使って minhash を算出する。
ROSE による誤植修正のための Lexical Preserving Hashing によるマッピング例: 「red nike shoos」 → 「red nike shoes」
Product Type Preserving Hashing
製品検索エンジンでは、クエリの製品タイプを理解することが関連した高品質な検索結果を提供するためにとても重要である。
具体例: 「red nike shoes」 のクエリの製品タイプは 「SHOES」
ここで製品タイプをクエリから抽出するために、クエリのトークンに対して製品タイプの重みを計算する。製品タイプのトークンは QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction[30] という NER モデルによって抽出される。
製品タイプトークンが存在しなかった場合の重みは 1、1 より以上の場合は製品タイプトークンが抽出できたことになる。 製品タイプトークンの重み付けは W >1 で与え、チューニングした結果 W=10 が最も結果が良好製品タイプトークンは W というしきい値で管理される。
Theoretical Analysis
アルゴリズムの理論解析について。 だが、知識がまったくないので、割愛することにした。
オフラインでの実験
データセット
約 6 億の検索品質が高いクエリを Amazon 検索からサンプリングして、評価のためのキャッシュ対象にする。
ここでは、Xichuan ら A Dual Heterogeneous Graph Attention Network to Improve Long-Tail Performance for Shop Search in E-Commerce. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3405–3415 [19]と同じ評価の枠組みで評価を行った。
クエリの評価データセットは頻度ごとに分割された3つのバケットを用意
NQ(Normal Queries): 頻度が上位 33%(1 つめの 3 分位数)のクエリHQ(Hard queries): 頻度が上位 34%-66% (1 つめの 3 分位数)のクエリLTQ(Long-tail queries): 頻度が上位 67%-100% (3 つめの 3 分位数)のクエリ
ランダムに上記のクエリを一ヶ月以上の検索ログから選択して収集する。3つのバケットは 1000 のクエリが存在してる。ドメインエキスパートによる判断により、ROSE の仕組みにより re-map された結果が元のクエリが書き換えられても意図が同一かどうかの 2 値(relevant or irrelevant)によって評価。
実験デザイン
2つの指標に対する仮設
- Robustness: どれぐらい ROSE は正確か?
- Efficnency: どれぐらい ROSE のインデキシングと検索処理は効率的か?
それらの仮設検証のために
R-LP: 提案手法。ROSE の lecical preserving hasing。 ハッシュテーブルの数は L=3 6 かつ、ハッシュの数は $K=3$R-PT: 提案手法。ROSE の product type preserving hasingEC: 完全一致によるキャッシュ実装BF: ROSE の検索アルゴリズムを力まかせ探索に置き換えた手法。類似度の尺度として DP を使って編集距離を計算する。FC: FAISS のアルゴリズムを使って ROSE のインデキシングと検索アルゴリズムを置き換えた手法。クエリの埋め込み空間は Semantic Product Search を使って用意。
評価指標としては、一般的な Precision, Recall, F1 を採用。
各指標の具体例としては、 例えば「red nike shoes」という original intent となるクエリが存在するとする。この「red nike shoes」と original intent は同一だが、語彙的な誤りによって「red nike shoos」、「red nike shooes」などのクエリが存在する。
これら、「red nike shoes」を original intent とするクエリ数が 20 件あり、以下のような分布になっている。
- 「red nike shoes」: 10 件
- 「red nike shoos」: 5 件
- 「red nike shooes」: 5 件
例えば、完全一致キャッシュでは、「red nike shoes」とう文字列に対して lool up を行い、
- precision: 100%
- recall: 50%
となる。
そして、ROSE-LP が 「red nike shoos」を「red nike shoes」に対して map ができたとする。(「red nike shooes」の map は失敗)
- precision: 100%
- recall: 75%
となる。
上記のように誤植が含まれるクエリをどれだけ各種手法で書き換えることができたかが、評価指標となっている。
全体を通した実験結果
検索性能
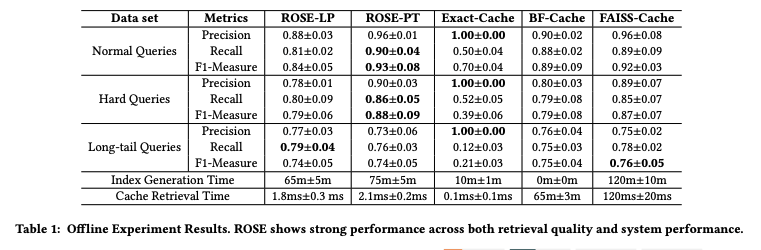
NQ, HQ に対しては ROSE-PT が最も性能が良く、LTQ に対しては ROSE-LP の性能が良かった。
システム性能
ROSE-LP は 60m でインデックス生成を完了。ROSE-PT は 75m。
NOTE: 論文中だとシステム性能としても性能が良いと書いてあるが、他の手法のほうが早いのでこの書き方は実際どうなんだろう。と思いつつも、検索性能がこれだけ上がって cache index 作成も 65m だけで済んでいるなら全く問題なさそう。
検索面では、力まかせ探索だと 65m(ms ではない)検索に時間がかかるらしいので、使い物にならなさそう。FAISS が 120ms 必要な中で ROSE は LP, PT ともに 3ms 以下という驚異的な速度。
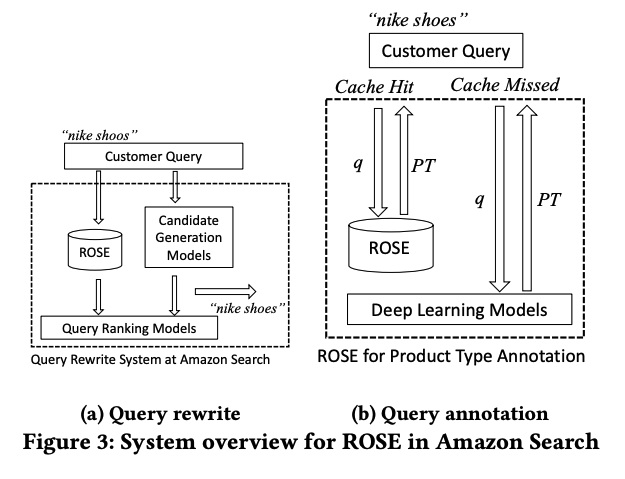
図 3 では、ROSE が担っている2つのコンポーネントを解説。
- (a) 誤植の問題を解決するクエリ書き換え。「nike shoos」という誤植のクエリが来た際に、「nike shoes」に書き換え
- (b) 深層学習モデル高速化のためのキャッシュ上での製品タイプ予測。Cash Hit した場合、ROSE によってクエリ(q)の製品タイプ(PT)を返す。キャッシュヒットしなかった場合は、深層学習モデルによってクエリに製品タイプの推論を行い、返す。
SYSTEM DEPLOYMENT IN AMAZON
ROSE for Query Rewrite
顧客が誤植によるクエリクエリを入力してきた際にクエリ書き換えを行うために実際に ROSE をデプロイ。使った手法は ROSE-LP。これによって、検索結果がそもそも低品質なクエリが高品質な検索結果として提示されるようになった。
オンラインのクエリ書き換えの結果はドメインエキスパートにり測定・評価され、良好な結果となった。 また、複数のビジネス指標も有意に改善された。
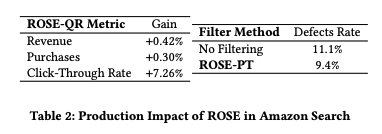
NOTE: CTR +7%ってすごくないですか…? 今までも、Amazon なのでもちろん Query Understanding に取り組んでいたと思うんだが、従来のクエリ書き換えよりも更に良くなったということだろうか?実際は ROSE によって検索の応答速度も改善されているので、変数は2つとなり難しいところではある。 また、Amazon の規模での利益 0.42% 上昇って半端ないですね。深層学習モデルのキャッシュでもあるので、特徴量の前処理改善にもなっていることに気がついた。
ROSE for Product Type Annotation
「red nike shoes」のようなクエリは、クエリから正しい製品タイプを特定することで、正しい製品を検索できたり、製品タイプによって検索結果を変更することが可能。
500 万-1000 万の規模の高頻度なクエリに対して、クエリから特定の製品タイプへマッピングする ROSE を実装。
ROSE は受け取った tail query に対して、そのクエリをキャッシュされたいくつかのクエリにマッピングし、そのクエリと紐付いている製品タイプを tail query の製品タイプの予測結果として使用する。
検索体験への影響を評価するため、ROSE の商品タイプ予測モデルを用いて、誤った商品タイプを持つ無関係な検索結果をフィルタリングし、このシステムを Amazon.com にデプロイし商品検索エンジンにおいて、ROSE により商品タイプを認識した場合としない場合の検索結果の不具合率(Defects Rate)を測定。
製品タイプ不良率(Product type defect rate)とは、検索結果の上位 16 件に含まれる商品のうち、製品タイプが誤っている数として定義。
表 2 より、ROSE による製品タイプを予測することで、欠陥率が 1.7%減少し、ユーザーエクスペリエンスが大幅に改善されたことがわかる。

図 4 では ROSE によって予測された製品タイプのフィルターを通した結果の違いが示されている。
NOTE: でもこの部分ではビジネス指標について触れていないということは、欠陥率しか改善しなかったのかなと邪推した。(それでも十分凄いけど)
社内の検索勉強会の発表順が回ってきたので、最近見つけた面白そうな論文である ROSE を読んでみた。 読んでいて非常に面白い論文で手法もさることながらビジネス指標もリフトさせているの本当にすごいし、価値がありますね。 この成果を公開してくれた Amazon に感謝
面白い論文は、引用する論文もイケているので周辺知識を深堀りしたい際に辞書的に使えるのもありがたい。
クエリの書き換えをキャッシュ(ROSE)に搭載して、システム的に密結合になったり、運用面で大変になったりしないのかなと思いつつも、これだけ性能が良いのならそれらを補って良い事だらけではと感じた。
振り返ってみると最近 Amazon が公開してくれている検索ネタを今回含めて 3 連続で読んで解説していたが
- Daria Sorokina さんによる、 Amazon 検索ランキングの奥深さ at MLconf SF 2016
- Amazon が e コマース検索を Lucene により、どうスケールさせているか at Berlin Buzzwords 2019
それくらい面白い論文が多いのと e コマース検索だと飛び抜けて先進的な取り組みをしている印象。
次は The First International Workshop on INTERACTIVE AND SCALABLE INFORMATION RETRIEVAL METHODS FOR ECOMMERCE (ISIR-ecom) の別の採択論文を読む。
おそらく次に読むのは
E-commerce Product Attribute Value Validation and Correction Based on Transformers: Le Yu, Haozheng Tian, Yun Zhu, Simon Hughes and Aleksandar Velkoski
関連しているかもしれない記事
- Web 検索とデータマイニングのトップカンファレンス WSDM2022 で気になった研究
- Amazon検索ランキングの奥深さ at MLconf SF 2016
- クエリ分類(Query Classification) について社内の勉強会で話してきた
- TFXの歴史を振り返りつつ機械学習エンジニアリングを提案する論文「Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)」
- 機械学習システムの信頼性を数値化し、技術的負債を解消する論文「 The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction」
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。