Googleによる機械学習の実応用をテーマにしたCoursera の講義は、機械学習プロジェクトに携わるなら一度は見ておいても損はない
過去に執筆した記事1を見返していたら
そういえば講師陣がめちゃくちゃ良いこと言ってるんだけど記事内に掲載してなかったなと思い、動画を見返すと今でも学びが多かったので、講義のスクリーンショットを見返しつつ筆をとってみた。
今見たら、日本語版の講義 How Google does Machine Learning 日本語版も公開されているので、興味の湧いた方はぜひ受講しましょう。Certificate を発行しないなら無料で受講できると思います。 講義内容の説明は、過去記事1で行っているので気になる方は御覧ください。
機械学習プロジェクトの努力の割当: 期待と現実
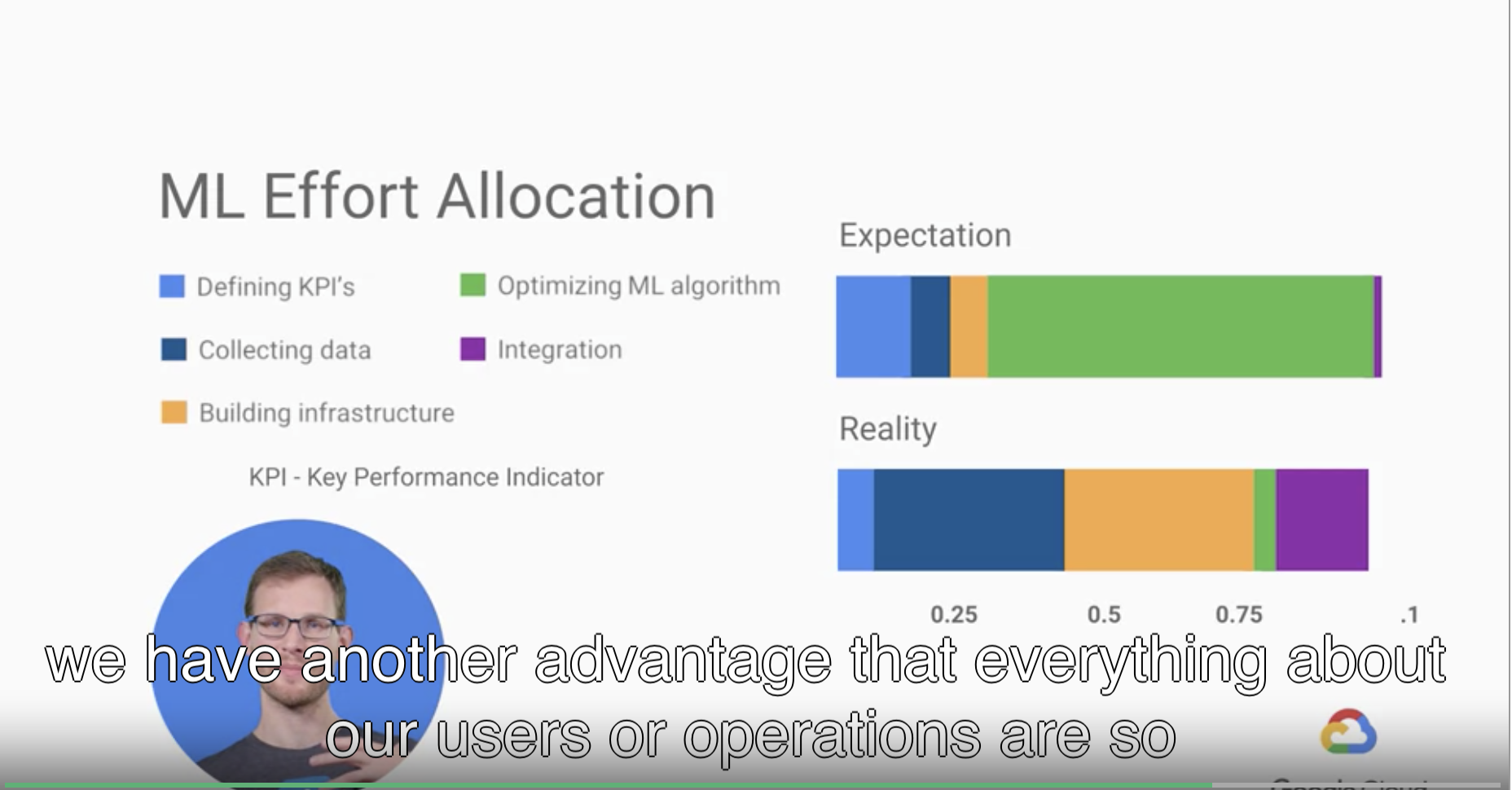
ML Surprise https://www.coursera.org/learn/google-machine-learning/lecture/aUjhG/ml-surprise
Hidden Technical Debt in Machine Learning Systemsと同じ話ですね。上記の論文でよく参照される図よりも、
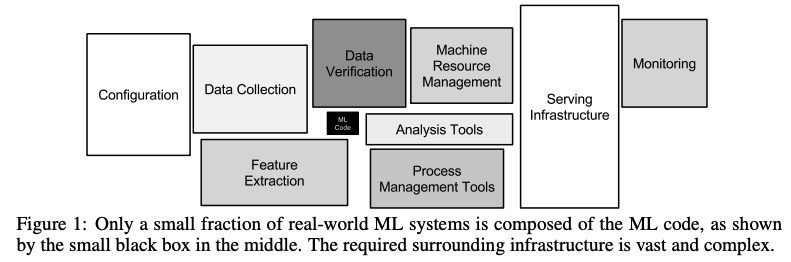
Hidden Technical Debt in Machine Learning Systemsから引用
機械学習プロジェクトを
- KPI の定義
- データ収集
- インフラ構築
- モデルの最適化
- システムインテグレーション
上の 5 項目で分けて、棒グラフの各項目が割合と順序を示しているので更にわかりやすいですね。
機械学習のシステム面かプロジェクト面のどちらに注力しているかという話ですが、プロジェクト面まで包括して説明しているのは良いですね。
機械学習で避けるべき上位 10 個の落とし穴
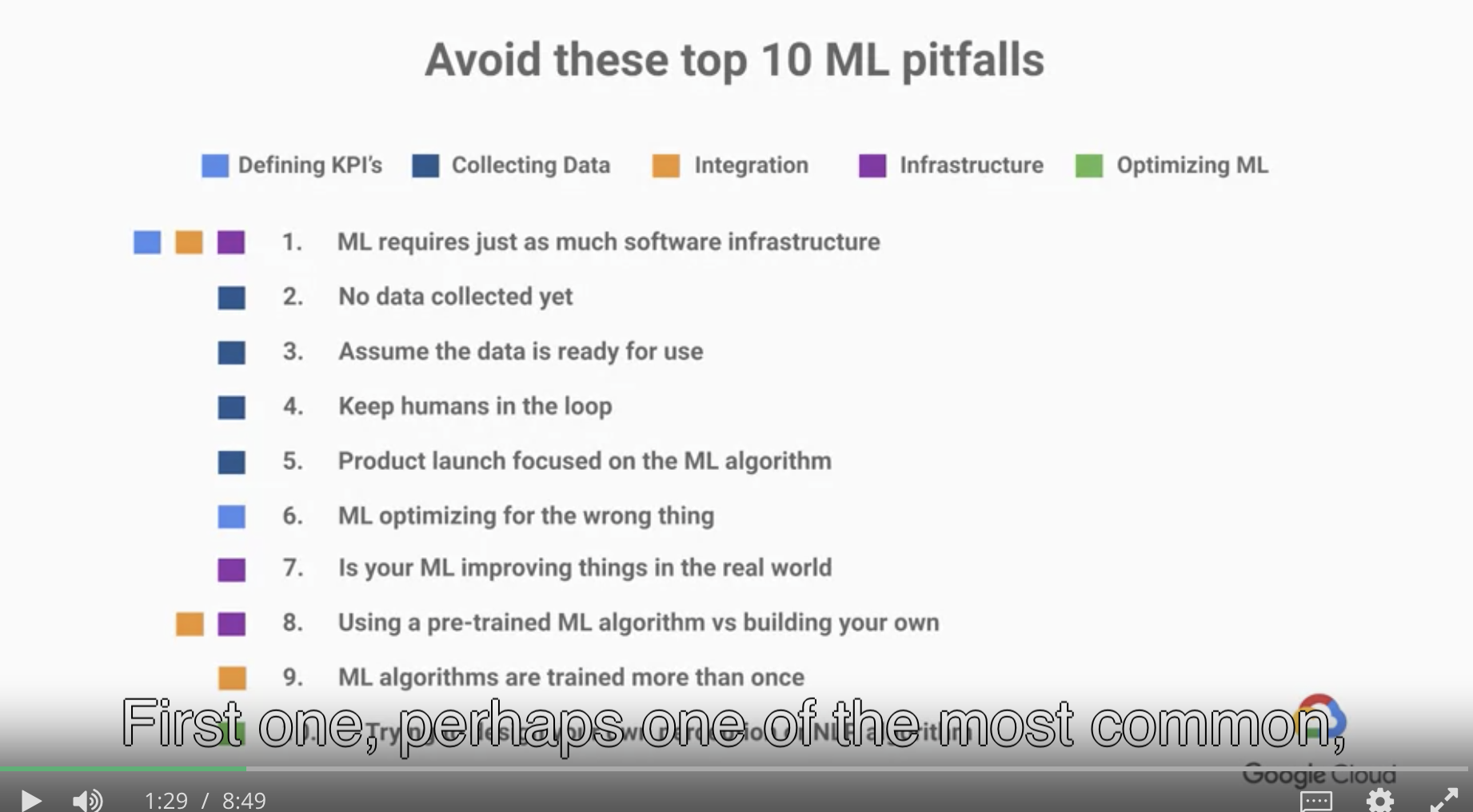
The secret sauce https://www.coursera.org/learn/google-machine-learning/lecture/BdsV6/the-secret-sauce
講師陣が Google 内部でのインタビューを行い、機械学習プロジェクトのアンチパターンのランキング Top10 を公開してくれています。
アンチパターンの列挙ですが、肯定文と否定文が混じっているので、否定文で統一しています。
機械学習の知識と同じくらい、ソフトウェア開発とインフラストラクチャの知識・経験を要求される
まだデータを収集していなかった
データが既に使える状態だと仮定していた
NOTE:例えばデータは収集されているが使える状態ではないとかですね。CSV ではなく、PDF でデータが保存されていたり、目当てのデータを取得するのに前処理をしないとそもそも取得できないなど… 過去に主催した勉強会でも同じような事が言及されてます。 @yuzutas0 さん、あらためて登壇ありがとうございました!
Human In The Loop を維持していなかった
NOTE:ここで言及される Human In The Loop (HITL)は、機械学習モデルのライフサイクルの中に、人間によるデータのレビューを設置することを指している。広義的な Human In The Loop ですね。Active Learning の事を Human In The Loop と定義されたりしていますが、機械学習モデルのライフサイクルに人間が介在することが一貫しています。
機械学習の機能に注力したプロダクトをリリースする
- 機械学習の機能を作成するためにはまず大量のデータが必要なので、まず基本となる機能で顧客を集めてデータを収集しないと鶏と卵の問題に陥る
違う問題に対して機械学習で最適化を行ってしまった
- 例えば、Google 検索を例に上げると、CTR(クリック率)のみに着目すると、悪意のある記事やフェイクニュースなどがどんどん検索ランキングの上位にきてしまう。
機械学習モデルによって、現実世界の指標がどれくらい改善されたか測定していなかった
- 成功したかどうかの判定ができないので、この機械学習モデルを使ったプロジェクトの継続提案を上司にすることができない
学習済みモデルを使うべきか、自分自身でモデルを 1 から作るべきか
- 自分で 1 からモデルを作らずとも GCP の Vison API など実際は提供されている機械学習の API を使えば事足りこともある。本当に機械学習システムを 1 から作るのは大変
NOTE:個人的には、Billing cost などの問題もあるので、その時の状況次第ですよね。アクセス数が限られているなら、Vision API も適切な場合もあるし、自社で作ったほうが良いこともある。状況を適切に判断することが大事
機械学習モデルはデプロイ後に再学習が必要だったことを知らなかった
- 基本的に、リリース後に何度もモデルの再学習は必要になる。そのため再学習が簡単になるような仕組みづくりに対して投資をしましょう
標準的(当該領域で研究されている)な認識モデルを参照せずに、独自の認識モデルを作成する
NOTE:ここで意味しているのは、研究領域で何十年も研究されているので自分独自の認識モデルを作成する必要はなくいい、それらを参照しましょうねという意味
ここからは、各講師陣の名言シリーズです。 Slack などの返信にこの画像を使うと楽しいかもしれません。
データは無いけど、機械学習がやりたいんです

あなたは機械学習をしたい、しかしまだデータを集めていない…

全力で機械学習をするのをやめてください。あなたにはデータが必要です。
まずはデータ、データが大事

データは必ず勝つ (機械学習の実応用において、データが最も重要。)
機械学習デザインパターンの第 1 著者の GCP の Lak さんの名言です。 そう、良いデータを集めれないと、何も始まらない、データを集めることで勝機が必ず生まれる。
関連しているかもしれない記事
- 2021年05月時点で自分が実践している MLOps の情報収集方法
- TFXの歴史を振り返りつつ機械学習エンジニアリングを提案する論文「Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)」
- MLOps の国際会議 OpML'20 に、機械学習を活用した商品監視の改善に関する論文が採択されたので登壇してきた
- 機械学習システムの信頼性を数値化し、技術的負債を解消する論文「 The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction」
- 機械学習システムの信頼性を数値化する論文「 What’s your ML test score? A rubric for ML production systems」
📮 📧 🐏: 記事への感想のおたよりをおまちしてます。 お気軽にお送りください。 メールアドレス入力があればメールで返信させていただきます。 もちろんお返事を希望せずに単なる感想だけでも大歓迎です。
このサイトの更新情報をRSSで配信しています。 お好きなフィードリーダーで購読してみてください。
このウェブサイトの運営や著者の活動を支援していただける方を募集しています。 もしよろしければ、Buy Me a Coffee からサポート(投げ銭)していただけると、著者の活動のモチベーションに繋がります✨
Amazonでほしいものリストも公開しているので、こちらからもサポートしていただけると励みになります。