検索エンジンOSS勉強会第1回の発表資料
発表での議論を基に改修予定
https://home.apache.org/~mikemccand/lucenebench/VectorSearch.html
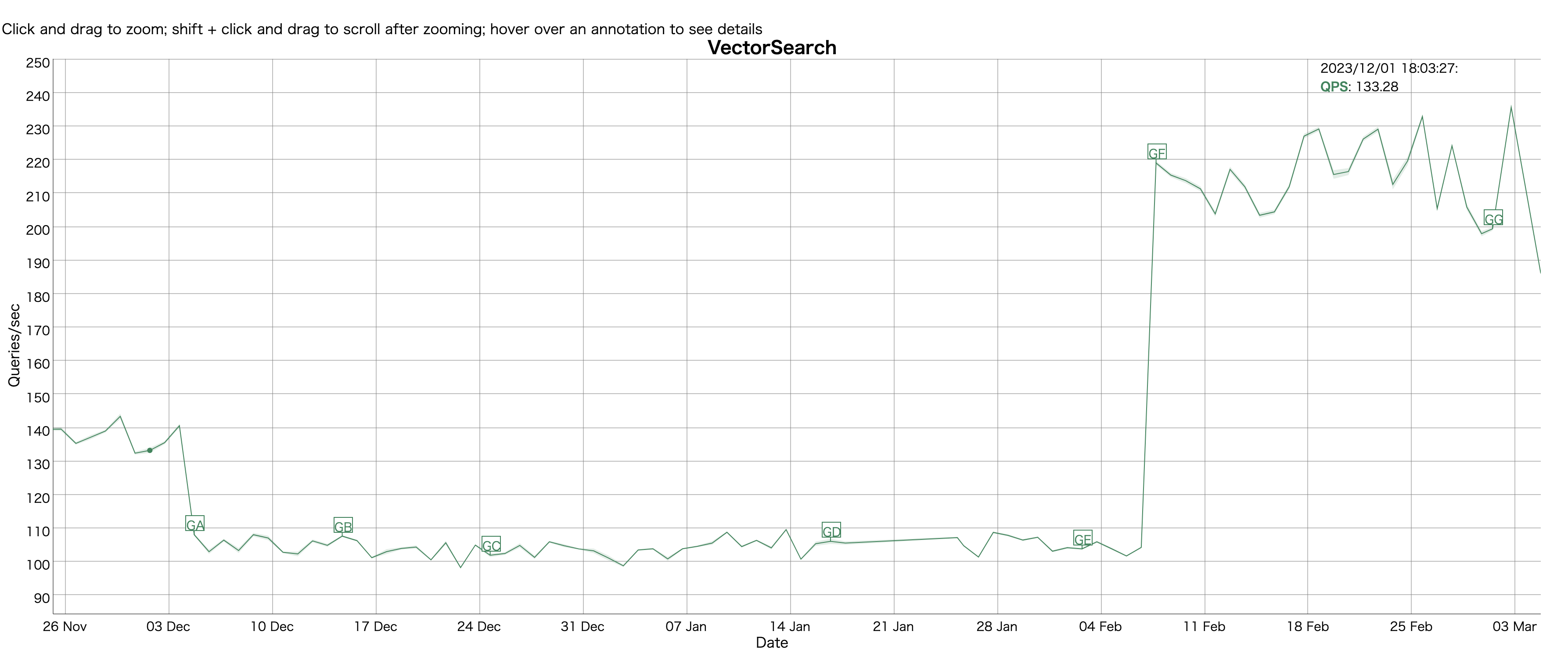
768次元のword embedding のベクトルに対して、近似近傍探索の結果のベンチマーキング。
Lucene Nightly Benchmarking での大きな改善
GE: 104QPS → 219QPS
GE: 近似近傍探索で複数セグメントに対して並行に検索
Elasticsearch のエンジニアの人が作成している
Lucene のセグメントの概念
docs→file→segment→index
+- Index 5 ------------------------------------------+
| |
| +- Segment _0 ---------------------------------+ |
| | | |
| | +- file 1 -------------------------------+ | |
| | | | | |
| | | +- L.Doc1-+ +- L.Doc2-+ +- L.Doc3-+ | | |
| | | | | | | | | | | |
| | | | field 1 | | field 1 | | field 1 | | | |
| | | | field 2 | | field 2 | | field 2 | | | |
| | | | field 3 | | field 3 | | field 3 | | | |
| | | | | | | | | | | |
| | | +---------+ +---------+ +---------+ | | |
| | | | | |
| | +----------------------------------------+ | |
| | | |
| | | |
| | +- file 2 -------------------------------+ | |
| | | | | |
| | | +- L.Doc4-+ +- L.Doc5-+ +- L.Doc6-+ | | |
| | | | | | | | | | | |
| | | | field 1 | | field 1 | | field 1 | | | |
| | | | field 2 | | field 2 | | field 2 | | | |
| | | | field 3 | | field 3 | | field 3 | | | |
| | | | | | | | | | | |
| | | +---------+ +---------+ +---------+ | | |
| | | | | |
| | +----------------------------------------+ | |
| | | |
| +----------------------------------------------+ |
| |
| +- Segment _1 (optional) ----------------------+ |
| | | |
| +----------------------------------------------+ |
+----------------------------------------------------+
このStackOverflow で共有されているこの公式ドキュメントは理解しやすかった
Apache Lucene - Index File Formats
- 2.9.4のやつなので最新版のpage を探しだせれば差し替える
Lucene の KNN の解説
Lucene comitter の Mike Sokolov さんの発表がわかりやすい
実際に作成されたPRを読んでみる
実際の複数セグメントを並行検索する処理の例 ref
AbstractKnnVectorQuery.java 内で KNNベクトル検索の並行検索がサポートされた
このクラスは名前の通り、近似近傍探索(kNN)を扱うクラス。
// k は kNNの k, IndexSearcher は名前のまんま
KnnCollectorManager knnCollectorManager = getKnnCollectorManager(k, indexSearcher);
// TaskExecutor は並行実行を担当する
TaskExecutor taskExecutor = indexSearcher.getTaskExecutor();
// LeafReaderContext はセグメントレベルで検索を効率的に実行可能なコンポーネント
List<LeafReaderContext> leafReaderContexts = reader.leaves();
List<Callable<TopDocs>> tasks = new ArrayList<>(leafReaderContexts.size());
for (LeafReaderContext context : leafReaderContexts) {
tasks.add(() -> searchLeaf(context, filterWeight, knnCollectorManager));
}LeafReaderContext の解説
Lucene での検索処理における LeafReaderContext の役割とその重要性を、より具体的な例を交えて解説。 Leaf はセグメントを意味していると解釈
Lucene におけるインデックスは、複数のセグメントに分けられており、各セグメントは独立したインデックスとして扱われる。このアーキテクチャにより、データの更新や検索の効率化が図られている。 たとえば、大規模なドキュメント集合に対する更新や追加が発生したとき、全体のインデックスを一から再構築するのではなく、新しいセグメントが作成され、最終的には既存のセグメントとマージされることでインデックスが更新される。
具体例: 検索処理
ユーザーが “Lucene” というキーワードでドキュメントを検索する場面を想定 Lucene のインデックスは複数のセグメントから構成されているため、検索処理は以下のステップで行われる
- クエリ解析: ユーザーの入力から検索クエリが生成されます。この例では、“Lucene” という単語を検索するクエリです。
- セグメントごとの検索: Lucene は、インデックス内の各セグメントに対してクエリを実行します。ここが
LeafReaderContextの出番。インデックスの全セグメントに対応するLeafReaderContextオブジェクトのリストを通じて、それぞれのセグメントに対して独立してクエリが実行されます。
例えば、インデックスに 3 つのセグメントがあった場合、
LeafReaderContext1を使ってsegment 1 を検索LeafReaderContext2を使ってsegment 2 を検索LeafReaderContext3を使ってsegment 3 を検索
各 LeafReaderContext からは、そのセグメント固有の情報(ドキュメントID、頻度など)にアクセスするためのインターフェースが提供されます。この手順により、各セグメントから “Lucene” が含まれるドキュメントが検索されます。
- 結果の集約: セグメントごとの検索結果を集約して、最終的な検索結果をユーザーに表示します。このプロセスでは、各セグメントから得られたドキュメントIDを、全体のインデックスにおける一意のドキュメントIDに割り当て直す必要があります。この割り当ても、
LeafReaderContextを通じて処理されます。
この例では、LeafReaderContext の役割がセグメントレベルでの検索処理の実行とその結果の取り扱いにどのように影響するかを示している。具体的には、LeafReaderContext は検索クエリのセグメントごとの実行を助け、セグメント内の情報に対するアクセスを提供し、さらに全体の検索結果を集約する際の橋渡しをします。また、新しいデータがインデックスに追加された場合や、セグメントがマージされた場合にも、LeafReaderContext が更新されることで、検索クエリの正確さと迅速さを保証している。
このPRで導入された KnnCollectorManager について
protected KnnCollectorManager getKnnCollectorManager(int k, IndexSearcher searcher) {
return new TopKnnCollectorManager(k, searcher);
}- KNNCollectorManager は KnnCollectorを管理
-
- KnnCollector は、近傍結果からkNN結果を収集する
-
- TopKNNCollectormanager は KNNCollectorManager のサブクラス(のようなもの)
concurrencyがサポートされている場合、BlockingFloatHeap 内に、すべての葉のグローバルトップスコアが収集される (既存のCollectorManager を基に作成したらしい)
public class TopKnnCollectorManager implements KnnCollectorManager {
// 何個のドキュメントを収集するか
private final int k;
// すべてのセグメントを跨いで収集されたトップスコアを追跡するために使用される、グローバルスコアキュー
private final BlockingFloatHeap globalScoreQueue;
public TopKnnCollectorManager(int k, IndexSearcher indexSearcher) {
// 複数のセグメントが存在するかを確認
// ここでやっと理解したが、 leaves って segment を指している模様... (segment は index の leaves と考えられるから? )
boolean isMultiSegments = indexSearcher.getIndexReader().leaves().size() > 1;
this.k = k;
// 複数のセグメントがあった場合に、k要素を持つBlockingFloatHeapインスタンスを初期化してglobalScoreQueueに割り当てる。そうでなければ、globalScoreQueueをnullに設定
this.globalScoreQueue = isMultiSegments ? new BlockingFloatHeap(k) : null;
@Override
public KnnCollector newCollector(int visitedLimit, LeafReaderContext context) throws IOException {
// 単一セグメントの場合
if (globalScoreQueue == null) {
return new TopKnnCollector(k, visitedLimit);
// 複数セグメントの場合
} else {
// 複数セグメントを並行検索する MultiLeafKnnCollector を利用する
return new MultiLeafKnnCollector(k, globalScoreQueue, new TopKnnCollector(k, visitedLimit));
}
}
}検索対象のセグメントが複数セグメントの場合に、並行検索を実行する MultiLeafKnnCollector
public final class MultiLeafKnnCollector implements KnnCollector {
// [0,1] の範囲で探索の貪欲度を制御する定数。値が1に近づくほど、より多くの最高類似度を局所的に保持しようとする。
private static final float DEFAULT_GREEDINESS = 0.9f;
// 全てのセグメントを通じて収集された最高の類似度スコアを保持するグローバルなキュー。
private final BlockingFloatHeap globalSimilarityQueue;
// そのセグメントがグローバルレベルで競争力を持たない場合に、最高の類似度(類似性スコア)をローカルに蓄積するためのキュー
private final FloatHeap nonCompetitiveQueue;
// 初期値DEFAULT_GREEDINESSを使用する探索の貪欲度
private final float greediness;
// 定期的にグローバルキューに更新る局所的な類似度スコアを保持するキュー
private final FloatHeap updatesQueue;
// 局所的なキューとグローバルなキューを同期するための訪問されたベクターの数の間隔
private final int interval = 0xff; // 255
private boolean kResultsCollected = false;
private float cachedGlobalMinSim = Float.NEGATIVE_INFINITY;
// サブコレクター、つまり局所的な収集を行う抽象的なコレクター実装
private final AbstractKnnCollector subCollector;
/**
* Create a new MultiLeafKnnCollector. * * @param k 収集する近似近傍探索の結果数
* @param globalSimilarityQueue 全セグメントで収集された最高類似度スコアのグローバルキュー
* @param subCollector 局所的な収集を行うためのサブコレクター
*/ public MultiLeafKnnCollector(
int k, BlockingFloatHeap globalSimilarityQueue, AbstractKnnCollector subCollector) {
this.greediness = DEFAULT_GREEDINESS;
this.subCollector = subCollector;
this.globalSimilarityQueue = globalSimilarityQueue;
// 例えば、`k`が10で、`greediness`が0.9(90%の貪欲度)の場合、`(1 - 0.9) * 10` に基づいてこのキューのサイズは `1`(最小でも1)となります。これは、セグメントがグローバルに競争力がない場合にも、少なくとも1つの最高類似度スコアをローカルに保持することを保証します。
this.nonCompetitiveQueue = new FloatHeap(Math.max(1, Math.round((1 - greediness) * k)));
this.updatesQueue = new FloatHeap(k);
}
@Override
public boolean earlyTerminated() {
return subCollector.earlyTerminated();
}
@Override
public void incVisitedCount(int count) {
subCollector.incVisitedCount(count);
}
@Override
public long visitedCount() {
return subCollector.visitedCount();
}
@Override
public long visitLimit() {
return subCollector.visitLimit();
}
@Override
public int k() {
return subCollector.k();
}
@Override
// 与えられた document id と類似度スコアから、サブコレクターとローカル、グローバルキューにそれを追加する
public boolean collect(int docId, float similarity) {
// localSimUpdated は ローカルで類似度の更新があったかどうかのフラグ
boolean localSimUpdated = subCollector.collect(docId, similarity);
// 最初にk結果が全部集まった瞬間かどうかを判断する。
boolean firstKResultsCollected =
(kResultsCollected == false && subCollector.numCollected() == k());
// この瞬間に一度だけkResultsCollectedをtrueに設定する。
if (firstKResultsCollected) {
kResultsCollected = true;
}
updatesQueue.offer(similarity);
// グローバルレベルで更新が生じたかどうかを判定するフラグ
boolean globalSimUpdated = nonCompetitiveQueue.offer(similarity);
if (kResultsCollected) {
// もしk件の結果が既に集まっていれば、与えられた間隔(interval)ごとに、updatesQueueの内容をglobalSimilarityQueueに送り、キャッシュされたグローバル最小類似度(cachedGlobalMinSim)を更新し、updatesQueueをクリアする。
if (firstKResultsCollected || (subCollector.visitedCount() & interval) == 0) {
cachedGlobalMinSim = globalSimilarityQueue.offer(updatesQueue.getHeap());
updatesQueue.clear();
globalSimUpdated = true;
}
}
// ローカルまたはグローバルキュのどちらかが更新された場合にtrueを返す。つまり、呼び出し元はさらなる探索を適切に調整できるようになる。
return localSimUpdated || globalSimUpdated;
}
@Override
// 競争力のある最小類似度(つまり、これより低い類似度のドキュメントは考慮しない基準類似度)を返す
public float minCompetitiveSimilarity() {
if (kResultsCollected == false) {
// k件の結果が集まっていない場合、Float.NEGATIVE_INFINITYを返すことで、現存するすべての類似度が競争力を持っているとみなす
return Float.NEGATIVE_INFINITY;
}
// k件集まっている場合、サブコレクターの競争力のある最小類似度と`nonCompetitiveQueue`の最高類似度(または`cachedGlobalMinSim`)を比較して大きい方を返す。これにより、ローカルとグローバルの両方のコンテキストでの最小限の競争力のある類似度が確定される。
return Math.max(
subCollector.minCompetitiveSimilarity(),
Math.min(nonCompetitiveQueue.peek(), cachedGlobalMinSim));
}
...
}今回の実装のパフォーマンス比較実験
Recall は1-10%下がっているが、QPSが最大3倍になる。トレードオフはあるがOPSの向上に価値があるので、Recall の毀損は無視
https://github.com/apache/lucene/pull/12962#issuecomment-1919701631
まとめ
で複数セグメントに対して、並行して近似近傍探索を実行できるようになり、recall は少し既存しているが、QPSは Nightly Benchmarking で2倍ほど改善された。