MLOps の査読付き国際会議 2020 USENIX Conference on Operational Machine Learning (略称 OpML’20)に論文が採択されたので、登壇してきた。
MLOps の査読付き国際会議と OpML の立ち位置
機械学習エンジニアリング・MLOps の領域の会議でも一番有名なものとして 2018 年に発足したMLSysがあります。(ちなみに最初は SysML という名前でした)
このカンファレンスの傾向としては、アカデミアの研究者主体の発足経緯からアカデミアからインダストリーへの橋渡し的立ち位置となっています。
具体的には、発表者はアカデミアの方が大半でハードウェアから、モデルの OSS 公開など幅広く機械学習エンジニアリング・MLOps の周辺領域をカバーしています。
OpML はその一年後に、USENIXが母体の会議として MLOps を軸にした会議として誕生しました。
USENIX は SRECON、OSDI などを開催している団体です。
学術的なスタイルに則り、先端的な計算機システムの成果を論文として公開されています。MLSys と対称的にこちらはインダストリーからアカデミアへの橋渡し的立ち位置となっています。発表内容は企業での発表者が多く、実際の運用で得られた各企業の MLOps のベストプラクティスなどがメインで話されています。
個人的には OpML のほうが、MLOps のど真ん中を主体に置いているので MLSys よりも盛り上がってほしいなと思っています。
OpML’19 がどのような様子だったかは、以下の記事がわかりやすいです。
自分自身、機械学習エンジニアリングや MLOps 周りのカンファレンス情報などを追いかけていますが、この分野で査読付きかつ論文として残せる形式の国際会議は主に上記の2つの認識です。
KDD や COLING、NAACL などの国際会議でもインダストリートラックが常設されるようになって久しいですが、最近ではインダストリートラックだけではなく、積極的に実応用前提のワークショップ(ECNLP at ACL2020, IRS2020 at KDD2020など)が開催されており機械学習の理論と実応用の融合が進んでいます。
OpML’20 への投稿と採択で得られたもの
OpML’20 では下記2つの発表枠があり、投稿者がどちらかを選んで発表を行います。
- 査読付きで 20m の口頭発表
- 2 ページの査読付き論文+20m の口頭発表
OpML20 で推奨されるトピックでも、自分たちが持っているネタで
New model introduction into production (e.g., staging, A/B test)
において新規性(Novelty)があると考えて、ここからストーリーを組み立てていきました。
スケジュール感として投稿締切が 2020/02/25 で、その 1 ヶ月前の 1 月末から毎日 1 時間、Google Calendar で時間を抑えて同僚と集中的に論文の執筆を行いました。
最初にガッと 3 ページほど書いて、その後洗練させて 2 ページに圧縮して投稿しました。
あらめて添削や執筆をともに行ってくれた同僚たちに感謝します。
そして投稿の 1 ヶ月後に通知メールが来て採択を知りました。
添削を何度も繰り返して時間が迫るなかなんとか投稿できたという状態で、とりあえず投稿できて良かったなと感じていた最中だったので、採択通知が来て本当におどきました。
査読システムの良い点として、自分たちの投稿内容がその会議で発表足り得るものかがレビュアーからレビューされることです。
自分自身機械学習エンジニアとして働いていますが、その成果が査読を通して同じ分野で働いているエキスパートの第三者に認められたという事実が自分の仕事への自信に繋がりました。
その後 Reviwer の方に指摘された点を意識しつつ修正を行って、Camera Ready を無事に提出しました。
また今回は急遽オンライン開催へと変更されたので、動画投稿も必須になり初めての収録もなかなか難産でしたが無事提出することができました。
OpML’20 で採択された論文
採択された内容は以下のページにまとまっているので、もしご興味があればご覧ください。
内容を簡単にまとめると、
- C2C での出品商品への監視タスクで機械学習を導入して、Recall を改善
- Human In The Loop と組み合わせたバックテストにより、リリース時の機械学習モデルの劣化を事前防止
- 不均衡なデータ分布を考慮したモデルリリース後の新たな A/B テスト手法の考案による、意思決定の高速化
です。
Auto Content Moderation in C2C e-Commerce
論文
発表資料
講演動画
当日はオンライン開催で、発表内容は事前に YouTube で公開され、その後 Slack 上でリアルタイムに発表者に質問ができる Ask Me Anything (AMA)セッションが開催されました。
また、今回はオンライン開催になった影響で参加費は無料となりました。
AMA セッションで Chair の方がファシリテーターとなり、予想以上に活発な議論が生み出され驚きました。
オンライン開催になり、発表内容はすべて YouTube で公開され、アメリカへの渡航の必要がなくなり気軽に参加できるのは非常に良い流れだと思います。
一方で、日本からの参加だと深夜 01:00-02:30 の参加だったのでその点のみ非常に辛かったです。
懇親会などの偶発性を持った出会いなどはオンラインだとやはり、難しく感じました。
面白かった OpML’20 の発表まとめ
OpML’20 の発表一覧はこちらから確認できます。
ここから面白かった発表を抜粋して紹介させていただきます。
Twitter でもまとめていたのですが、記録のために分散させておきたいのでこちらでも記載しておきます
Runway - Model Lifecycle Management at Netflix

Runway という Netflix でのモデルのライフサイクルマネジメントツールの紹介
NetFlix で実際にあった課題
-
モデルを誰が作ったか、現在どんなモデルがあるのか、特徴量、変換、データはどんなものが使われているか
-
モデルのリリース、検証、モニタリングやアラートが標準化されていない
-
計算機資源の無駄遣いなど
上記の課題を解決するために Runway が作成された。
-
Runway は現状 A/B テストやカナリーテストは提供できていない
-
integration 周りは Jenkins を使って実現している
k8s を明示的に言及していないってことは多分使っていなさそうではある。
計画段階だが、Netflix で開発している機械学習のワークフローエンジンMETAFLOWと Runway のインテグレーションも視野に入れてるらしい。
一つの会社でこんだけ機械学習社内ツールが乱立してるのは競争力が非常に高いと感じた
データリネージなどの質問もされている
ガバナンスまわりを考えると、大企業だとデータリネージの必要性も最近わかるようになってきた。
More Data Science, Less Engineering: A Netflix Original
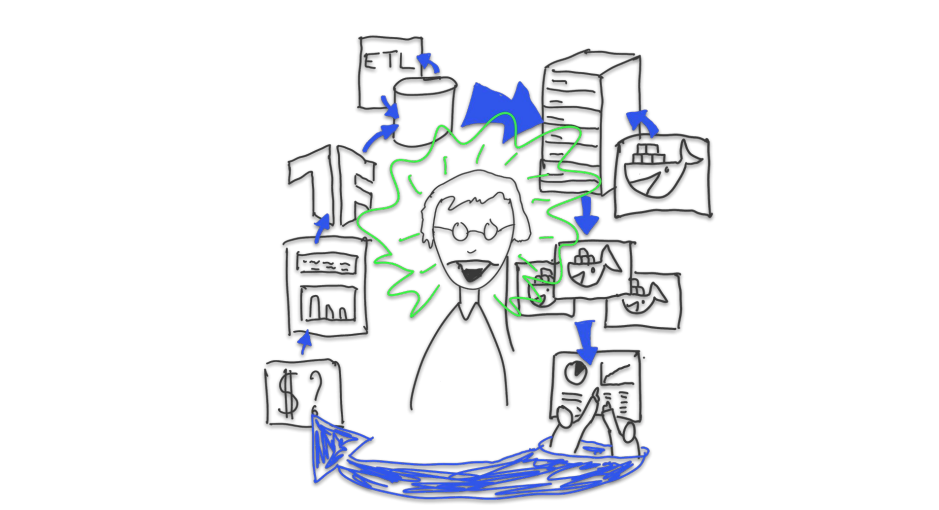
MLOPs NYC で公開された MetaFlow の話。
スライドでの Data Scientist の苦悩を描いたイラストが秀逸で面白かったです。
METAFLOW の Data Scientst のスキルを最大限に活かす思想は非常に共感できるので、どんどん発展してほしいです。
最近では R にも対応して驚きましたが、METAFLOW の思想であるMore Data Science, Less Engineering: A Netflix Originalに基づいていて非常に的確な対応ですね・
inside NVIDIA’s AI Infrastructure for Self-driving Cars

-
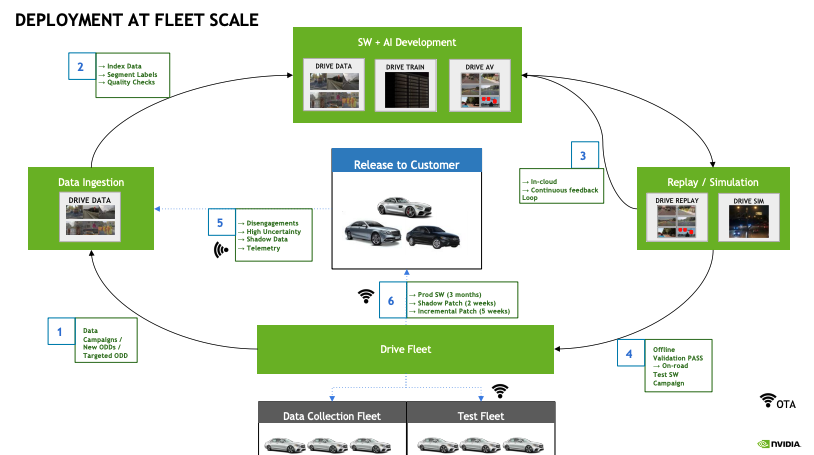
自動運転のためにデータの収集からモデルのデプロイ・シミュレーションまで一気通貫で開発
-
実世界での Ground Truth を考える
- 多種多様なデータ(LIDAR, Sensor, GPS. etc.)
- 100 種類以上の外的なシグナルの活用

スケールするデプロイのための、データの生成から、モデルの学習 → モデルの監査からシミュレーション・ハードウェアでの shadow patch を終えて、Prod にデプロイする流れ
Automating Operations with ML
-
https://www.usenix.org/conference/opml20/presentation/underwood
-
オペレーションでの機械学習活用について Google によるセッション
-
ほとんどの場合、機械学習の維持コストのほうが実際のインパクトより高い
-
単純なヒューリスティックは柔軟性に欠けるが機械学習と同等に役に立つ
発表者の Todd さんは他にも SRECON2019 に
All of Our ML Ideas Are Bad (and We Should Feel Bad)
となかなか刺激的なタイトルで、SRE の分野で機械学習の実応用はなかなかうまくいなかったぜと共有している…
How ML Breaks: A Decade of Outages for One Large ML Pipeline

日本語に訳すと、
機械学習システムの壊れ方:15 年以上経過した ML パイプラインがどのようにしてぶっ壊れてきたか
モデルの前提として
-
15 年以上まえから開発された機械学習パイプライン
-
10 年以上前からポストモーメンタムが行われている
-
定期的に 1 時間かけてモデルを新規データで学習
-
新モデルは学習後即、CD される

-
失敗の要因を 19 種類にまとめた。オーケストレーションの失敗、CPU 不足などなど

個人的には
-
NVIDIA の inside NVIDIA’s AI Infrastructure for Self-driving Cars
-
Google の How ML Breaks: A Decade of Outages for One Large ML Pipeline
が骨太で非常に面白い発表でした
MLOps という言葉が誕生して久しいですが、機械学習システムの開発と運用に置いて、何をやるべきなのかが構造化されてきています。
書籍では、日本語で読める良書として、仕事ではじめる機械学習
や最近では、Googler の方がオライリーで出版予定のMachine Learning Design Patterns
など非常に充実しています。
これからも、機械学習と現実世界の橋渡しとしてこの領域はどんどん掘り進められていくと思います。
MLOps はデータの活用を前提にしたシステム開発というとてもエキサイティングです。
もし OpML の発表が面白いと感じた方は、来年の OpML21 の口頭発表にも申し込んでみてはいかがでしょうか?