- Twitter’s Recommendation Algorithm
- 2023-03-31にEron Mask が以前から計画してた、Twitter の検索&推薦関連のシステムがGitHub で公開された。
- まさか本当に公開されるとは…
- twitter/the-algorithm: Source code for Twitter’s Recommendation Algorithm
- OSSとして公開された検索& 推薦システム
- 最初は、推薦だけなのかなと思いきや検索関係のコードも介されていることを発見
- Earlybird: Twitter の検索システムは Apache Luceneをベースにした、リアルタイム検索システム。論文はここ で、Blog記事は The Engineering Behind Twitter’s New Search Experienceは2011年に公開されている。
- Web検索はある程度成熟してきた分野だが、SNSのリアルタイム検索はまだ2011年当時いまだ未成熟で未開拓な分野
- Twitter で新たに開発したのが、 Earlybird と呼ばれるリアルタイム検索に特化した検索エンジン
- Lucene のNRT 機能が導入され始めたのが、2011年の終わり頃なので、このときには恐らくGAではないから、恐らく独自に作成した? Changing Bits: Near-real-time readers with Lucene’s SearcherManager and NRTManager
- この論文の貢献点
- Web検索とのインデックス構造の違い
- ロックフリーのsingle-writer, multi reader の 並行性モデル
- 1億人のActive User, 毎日2.5億件のツイート
- query latency 50ms, 10s 以内に検索可能になる
- リアルタイム検索の考慮すべき事項
- 低いレイテンシー、高速なクエリ評価
- データ挿入の即時性(web 検索はそこまでの即時性は必要ない)
- 並行したread, write
- fresh ness signal(いつ作られたかというシグナルがとても重要)
- 現在web でも有用なsignal になっているが、当時はそこまで重要ではなかった
- 関連事項
- 分散検索アーキテクチャ
- 面白そうな論文がめっちゃあるけど、紹介しきれないので割愛。
- クエリ評価
- 2 stage
- 1st: cheap BM25, PageRank, quality score など
- 2nd: expensive 1st の結果を候補にして、(基本的には機械学習による)Re-Ranking
- 2 stage
- その他
- 多種多様なドメインを扱うのは大変(画像、動画、ニュース、単なるツイートなど)
- 例えば news はそのニュースの内容を知った上でranking する必要があるし、ドメインごとに特性が異なる。それらを統合していくのも課題点
- 多種多様なドメインを扱うのは大変(画像、動画、ニュース、単なるツイートなど)
- 分散検索アーキテクチャ
- Earlybird 概要

- 3 signals
- 統計的シグナル: 何文字か、いつ投稿されたかなど、インデックスされた瞬間に把握している情報
- 反響シグナル (Resonance signal): リツイート数
- Searcher の情報
- score_sort と created_sortが毎回計算されて Blender(BFF)に返す
- この時、searcher のローカルソーシャルグラフに基づいてscore を計算している。これがソーシャル検索のキモ
- Java で作った理由
- Lucene を使いたい
- Twitter の Java 文化に合う
- Java の並行処理は理解しやすい
- 結果的に C/C++ に匹敵するパフォーマンスを出せている(と考えている)
- ソーシャル検索の宿命として、常に検索されるし常にindexing され続けている
- つまり圧倒的な並行処理を実現する必要がある
- multiple index segment(12個)
- 各々のセグメントは、大体840万のツイートを格納
- 一つのセグメントがwrite され、その他のセグメントはread only になるように設計されている(模様、コード読もう)
- active index: writable
- non-active index: read-only
- 32bit integer のポスティングリストとして設計
- 24bit: document id
- 8bit: term position(140文字なので8bit で十分)
- Earlybird は高速なインデキシング処理のために、インデックスを圧縮せずそのまま保存している。
- Twitter で新たに開発したのが、 Earlybird と呼ばれるリアルタイム検索に特化した検索エンジン
- Web検索はある程度成熟してきた分野だが、SNSのリアルタイム検索はまだ2011年当時いまだ未成熟で未開拓な分野
感想
これでだいたい概要をつかめたので、次はコードを読んでみたいなと思っています。 にしても、Twiter はマイクロブログという宿命か、ドキュメントの数、クエリ、増え方は EC と違って本当に桁違いです。 独自で検索エンジン作らざるを得なかった状況に追い込まれて、見事に成し遂げているのはすごいですね。 メンテンスとか大変そうですが…
余談
ChatGPT が活用された論文読解支援サービスを試しに使ってみたら、ものすごく良かった。
ChatPDF - Chat with any PDF! で、論文を見てみると、英語しか対応してなさそうだけど、日本語でプロンプトを打つと日本語で返された。おま国ではないのが ChatGPT の良いところだと思います。
https://www.chatpdf.com/c/lAAdzSaHgv8EbomIStV51 ファイルごとに誰からも閲覧可能な URL が生成されるみたいです。ここから見れます。
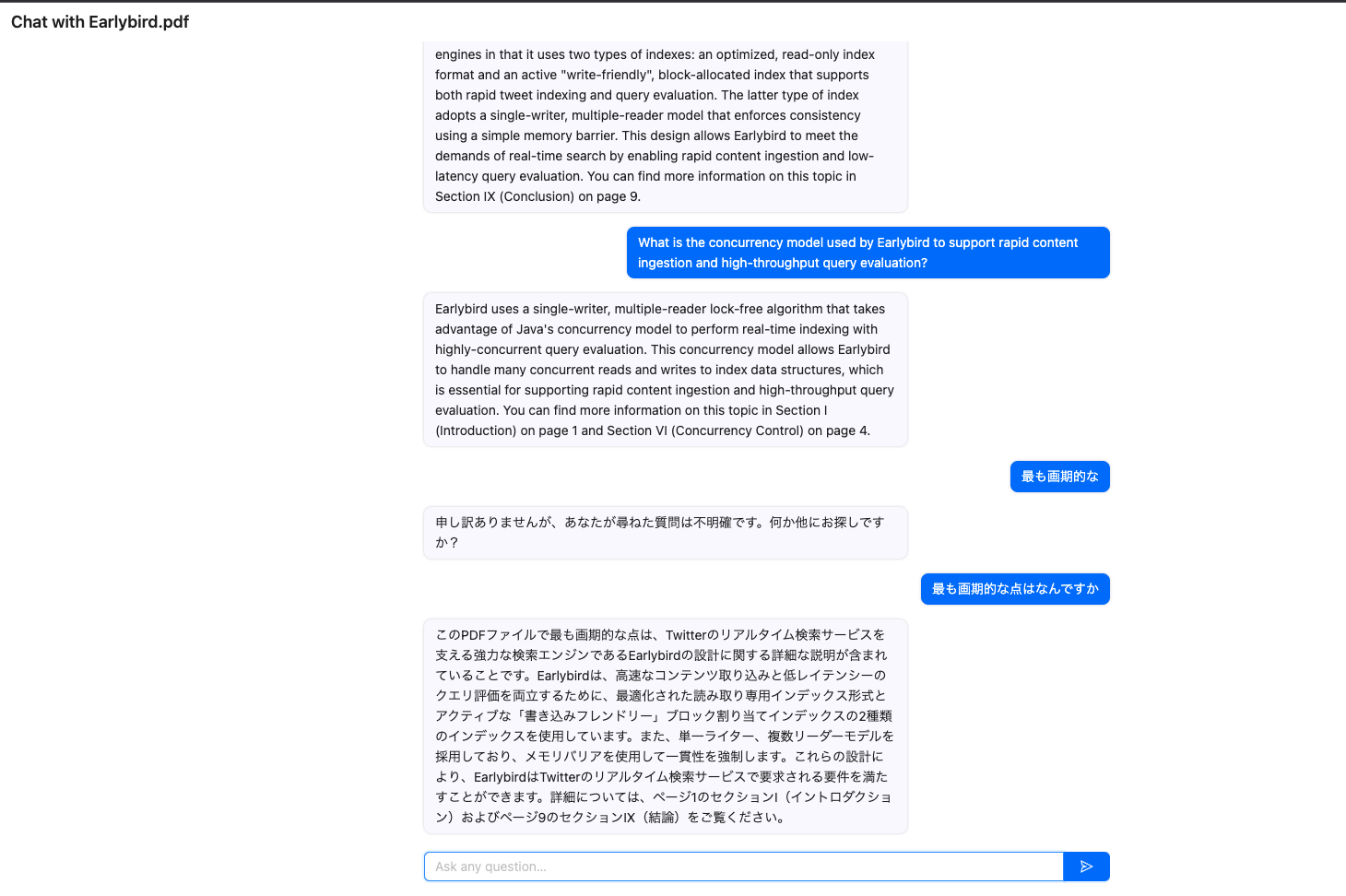
ChatPDF での質問
最も画期的な点はなんですか?
この PDF ファイルで最も画期的な点は、Twitter のリアルタイム検索サービスを支える強力な検索エンジンである Earlybird の設計に関する詳細な説明が含まれていることです。Earlybird は、高速なコンテンツ取り込みと低レイテンシーのクエリ評価を両立するために、最適化された読み取り専用インデックス形式とアクティブな「書き込みフレンドリー」ブロック割り当てインデックスの 2 種類のインデックスを使用しています。また、単一ライター、複数リーダーモデルを採用しており、メモリバリアを使用して一貫性を強制します。これらの設計により、Earlybird は Twitter のリアルタイム検索サービスで要求される要件を満たすことができます。詳細については、ページ 1 のセクション I(イントロダクション)およびページ 9 のセクション IX(結論)をご覧ください。
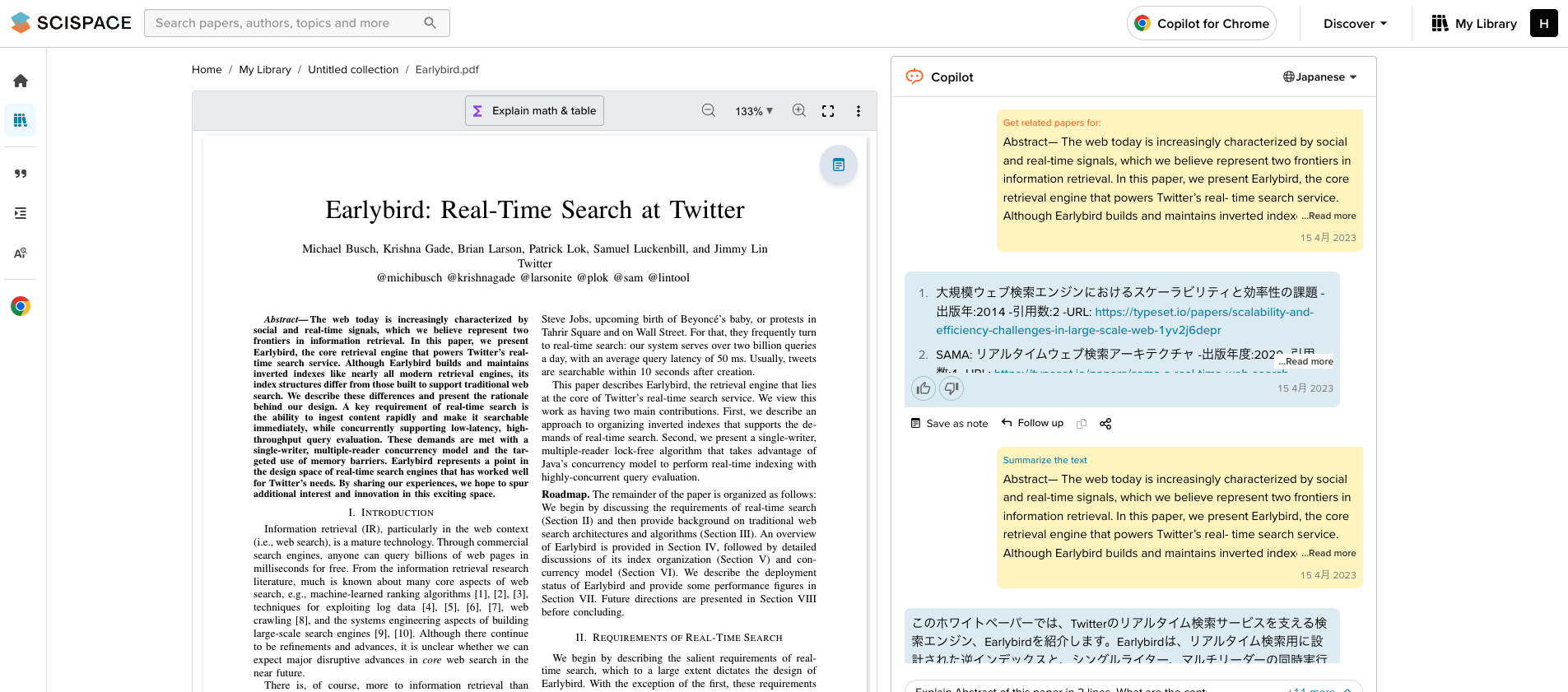
だけど、その後に SCISPACE というサービスを教えてもらい、触ってみたところ ChatPDF の完全なる上位互換だった。 返答を完全に日本語に固定できたり、予め論文に対して行う定型的な質問がプロンプトとして用意されている。 また、左ペインにアップロードした PDF が表示されて、ドラッグアンドドロップで選択した範囲の文章に対して要約させたり、説明させたりできるのはすごい便利です。
- The Engineering Behind Twitter’s New Search Experience 2011-05-31 公開