- Twitter’s New Search Architecture 2010-10-06 公開
- この時期に新しいアーキテクチャに移行
- MySQL による検索から Apache Lucene による検索へ移行
- この検索エンジン自体は、買収した会社が作成していた
- Twitter は Java で作られているから Lucene と相性が良い
- 要件
- 1000 tweets/sec
- 12000 queries/sec
- 1 billion queries / day
- 新しいアーキテクチャで、一桁大きい規模のトラフィックに耐えられることを期待している
- Tweet はリアルタイムなので、もちろん検索システムもリアルタイム性が非常に重要
- indexing latency も非常に重要
- tweet された 10 秒後には検索可能になってほしい
- indexer 自体のレイテンシは 1 秒以下である必要がある(indexer 自体はデータパイプランの一部でしかないため)
- Lucene を改造
- Lucene は素晴らしいが、リアルタイム検索を行うにはまだ足りない点がある
- メモリ内のデータ構造を書き直す。
- ポスティングリストを特に書き直す。
- ガーベージコレクションの改善
- lock free のデータ構造とアルゴリズム
- 逆順に走査可能なポスティングリスト
- 効率的なアーリークエリリターン
- 移行後
- システム全体の 5%しか利用していないが、50 倍近いツイートをインデックスできている。
- 移行したことでユーザーに利点は果たしてあるのか?
- 検索対象が非常に増えた(bigger index と書かれているが恐らく検索できる範囲が増えたのでは?)
- 多機能で拡張可能になったので、新機能をより多く試せるように
- Blender: Twitter Search is Now 3x Faster
- 2011-04-06 公開
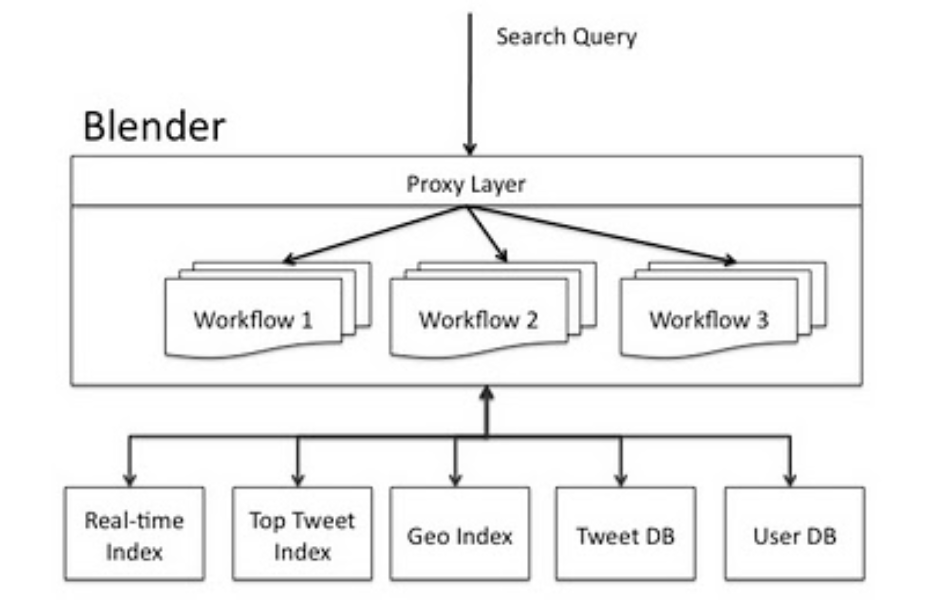
- Blender は Ruby on Rails から置き換えられた Java 製のフロントエンドサーバー
- Blender をリリース後 95%タイルレイテンシは 1/3 になった。具体的には 800ms から 250ms 、そして CPU 負荷は半分以下へ
- これによってキャパシティは 10 倍近く増強された
- 結果的にインスタンス数の削減に繋がり、コスト削減にもなった
- Ruby on Rails によるフロントエンド
- シングルスレッドの Rails worker プロセスが走り
- クエリのパーシング
- 検索エンジンに同期的にリクエストを投げる
- 集計し、結果を描画する
- 特に同期的にリクエストを投げる点が律速の原因だった。また、Ruby のコードは技術的負債が高まっており、検索システムの信頼性の向上が難しくなっていた
- 改善手法
- 完全な非同期リクエストにする
- バックエンドサービス(リアルタイム検索、トップツイート、地理情報)から結果を集計する